Battlefield Simulation
Automated Battlefield Simulation Command and Control Using Artificial Neural Networks
Stewart H. Jones, Ivan J. Jaszlics, and Sheila L. Jaszlics
Pathfinder Systems, Inc.
Lakewood, Colorado 80228
Abstract
Contemporary Distributed Interactive Battle Simulations are becoming increasingly large and complex and therefore, difficult to manage. The success of future projects will depend, in part, on the ability to manage aspects of the command and control of forces in an automated and highly predictable manner. Artificial intelligence in general and Artificial Neural Networks in particular offer attractive mechanisms to automate command and control. Pathfinder Systems has developed the Linear Interactive Activation and Competition (LINIAC) Model Artificial Neural Network, a high-speed, object-oriented model, for use in several battle simulations and has demonstrated that this is a feasible application of this technology. LINIAC is well suited for providing automated decision control and battle management functions for a variety of constructive battlefield simulations. It emulates the decision-making functions of tactical unit commanders and their staffs, as represented by roleplayer / controllers in command post exercises. LINIAC uses an object-oriented design that recognizes a situation pattern and provides a corresponding outcome in the span of several, or several tens of milliseconds. A key advantage of LINIAC is that its training is encoded in and initialized from an external data structure rather than hard-coded as rule-bases or algorithms. Therefore it is possible to replace or retrain LINIAC networks easily to meet new requirements without modifying code. LINIAC training uses a graphical interface so that trainers do not need computer language training or special computer skills. Experts with specialized knowledge can incorporate their knowledge into neural networks directly without requiring the services of a Knowledge Engineer. A trainer can typically enter two or three dozen training examples per hour. Pathfinder Systems has demonstrated the ability to use LINIAC artificial neural nets in several battle simulation programs to provide automated command and control of at least part of the forces in the simulation. The results of these projects has shown that using LINIAC neural networks can successfully emulate the human decision making element in battle simulations with results that are equivalent to what human roleplayers and automated rule bases are able to provide.
Introduction
A fundamental consideration in designing battlefield simulations is that they approach realism as faithfully as possible. One difficulty in simulating battlefield command and control is replicating the decision making process which it is based on. The purpose of many simulations is to train a part of its audience to make acceptable battle decisions. Here it is appropriate to have human operators perform decision-making functions. However using human roleplayers to make decisions for the Opposing Forces, or friendly adjacent and rear forces may be counter-productive and automated command and control may be highly desirable. To provide such automation, many current simulations rely heavily on decision algorithms and rule bases coupled with human roleplayers to provide the human element. Problems may develop because algorithms and rule bases may not be sufficiently error-free and human roleplayer resources are sometimes difficult to commandeer. Automation using algorithms and rule bases may also lack sufficient flexibility to meet changing scenario requirements without elaborate programming. Artificial Neural Networks (ANNs) offer a cost-effective alternative to algorithms and rule bases for generating or replicating human decision making. ANNs are effective because they are based on examples, rather than hard-coded implementations.
This paper describes an approach which Pathfinder Systems, Inc. (PSI) has taken to apply ANNs to automate Command and Control for military simulations. PSI has developed the LINIAC Neural Network model for Command and Control decision emulation. It has been used for demonstrations with the Brigade/Battalion Battle Simulation (BBS), within the BBS-SIMNET Interoperation project to generate decisions for SIMNET Semi-Automated Forces, and in ROLEPLAYER, a very simple battlefield simulation, which demonstrates a practical use of LINIAC neural nets at the platoon, company and battalion levels. Another example, currently under development by PSI and the MITRE Corporation, is the application of ANNs to the EAGLE battle simulation model. Currently, the EAGLE simulation relies heavily on rule-based decisions. This project intends to demonstrate the feasibility of replacing rule bases at lowest level of command and control in a complex simulation with ANNs.
The Need for Flexible AI Command and Control
There are some obvious difficulties with using algorithms and rule bases to replicate human decision making. Typically they are hard-coded and are difficult to change if the needs of the simulation change. Recent global military developments, such as the dissolution of the Soviet and Eastern Block forces and the emergence of third world military forces, have changed the command and control requirements for battle simulations. Today they must be flexible enough to accommodate a variety of military doctrines and modes of operation, often requiring rapid reconfiguration. If it is necessary to implement algorithms and rule bases using syntactically rigid programming or data-entry languages, their development requires programming technicians to translate the command and control requirements into the appropriate language syntax. The steps required to translate the knowledge of experts into a formalized syntax introduce the possibility of miscommunication and misunderstanding, which can result in program errors. Even when good understanding exists, logic errors can be generated inadvertently. A significant amount of testing is required to detect and remove such errors. Finally rule bases and algorithms usually must account for all possible contingencies when analyzing a problem so that unaccounted for conditions will not generate unintended results in the simulation. Significant engineering effort is needed to ensure that all reasonable situations are represented in the code.
Using Artificial Neural Nets for automated command and control can overcome many of these limitations. ANNs can be implemented as an object class with standard interface and decision methods. A simulation can then create many decision objects of that class, each with its unique environment consisting of input information and a “connection matrix” that encapsulates the behavior of a particular ANN. The decision method is a relatively simple mathematical process that is valid for a wide variety of decision applications. A well-designed ANN object can accommodate any compatible decision base and faithfully replicate the cognitive reasoning that it has been trained with.
It is possible to design training methods for ANNs using standard graphical interface techniques that do not require any programming expertise on the part of the trainer, so that knowledge experts can train them directly without having to rely on a technical interpreter. Experts can quickly, often intuitively, learn how to use such interfaces to train ANNs directly in sessions that last only an hour or two. Experts can also define the command and control variables using English words and phrases that make sense both to the trainer and the training audience. When training ANNs, it is not necessary to provide examples for all possible input combinations as it generally is with algorithms and rule bases. A neural net may have thousands to hundreds of thousands of possible input combinations, but a small, representative sample of the total is sufficient for adequate training. ANNs are very good at extrapolating the examples they were trained with to cover other, similar examples. The key to good training, of course, is to include examples that cover the broadest possible range of input conditions.
If a simulation must be able to accommodate multiple scenarios to reflect different military doctrines or modes of operation, then it is possible to train ANNs for each scenario and initialize appropriate ANN objects for the specified scenario with the required behavior when starting the simulation rather than modifying the simulation code. This technique also applies to automated command and control for multiple echelons. The decision structure for several echelons may be similar in that each echelon looks at the same set of conditions and makes equivalent decisions. The only difference may be that each echelon may use different reasoning to arrive at comparable decisions. Therefore it is possible to apply a single decision structure to several echelons, but have each echelon uses a set of ANN objects uniquely trained to reflect its individual reasoning.
Finally it is possible to train neural networks incrementally. If an ANN demonstrates inappropriate behavior within a simulation, it is possible to retrain it quickly. In fact, training through simulation scenarios is a very effective training method.
The Linear Interactive Activation and Competition (LINIAC) Model
As part of its research in using ANNs for command and control applications, Pathfinder Systems, Inc. has developed the Linear Interactive Activation and Competition (LINIAC) ANN Model. Figure 1 illustrates how the LINIAC model makes decisions. Each LINIAC ANN consists of an input vector, shown as downward pointing arrows, an output vector, shown as right-pointing arrows, and a connection matrix. The input vector defines a set of input conditions, where each condition can assume one of two or more states. The actual number of conditions and states for a given ANN is arbitrary, but cannot change once the ANN has been trained without requiring retraining. In the LINIAC model, each condition may assume only one state, which is expressed by a 1 value, while all other states for that condition are expressed by a 0 value (although weighted numerical values are also possible). The LINIAC output vector consists of one condition also with an arbitrary number of states. The black dots, shown at the intersection of each horizontal and vertical arrow, represent the neural connections between input and output vector elements and the size of each dot suggests the relative strength or “weight” of the connection. The weight determines how strongly each input state influences the corresponding state of the output vector. A LINIAC decision is always selected as the output state with the greatest cumulative value. The key to the successful operation of LINIAC is establishing the values of the connection matrix during training so that a given input pattern will always produce the outcome that the trainer has specified.

Fig 1. LINIAC artificial neural net concept
Neural Net Application to Automated Command and Control
There are many ways to apply neural nets to automated command and control, ranging from single neural nets to very complex decision structures composed of layers of neural nets. The remaining discussion will focus on the several examples/models developed by or under development by PSI. One advantage of the Neural Net approach is the ability to group relatively simple decisions into a complex decision structure. This is analogous to the way that complex organizational decisions are typically made. Another advantage is that this approach allows the designer to partition complex decisions into simple components that are much easier to design, understand and train.
The success or failure of the use of ANNs will depend heavily upon the validity of the design of the decision model. The model presented below is one of many potential concepts. The value of this approach is that simple elements can be designed, redesigned and reconnected into a structure that accurately represents the decision making process of a real military unit. A workable decision structure will probably be a hybrid of algorithms, rules and neural nets working together. Algorithms are needed to transform simulation data into data types (i.e. decision variables) that are appropriate for input into the ANNs of the decision structure. Not all types of decisions are best implemented through neural nets—when the number of input possibilities and the number of outcomes is small, algorithmic rules are usually a better choice. We tend to use neural nets when the possible combinations of the inputs, even if they are not fuzzy, can run into the thousands, or hundreds of thousands.
The training of a net is almost trivial if it is performed by a subject matter expert. What is very important is to determine the overall decision structure for an activity represented by an ANN (this can be, for example, a specific human C2 function, such as “armor BN S2—evaluate the current situation”). It is to be expected that a decision structure design will undergo an evolutionary process that will improve its realism. The principal elements of a design include the set of decisions (the ANNs) that the simulation requires at each command and control point, the structure of each decision process (the conditions and states of each ANN), the connections to the simulation data base and the interconnections between the selected ANNs. How individual ANNs are trained is of lesser importance initially, since training or re-training can occur after implementation.
The Roleplayer Model
PSI originally developed the ROLEPLAYER model to demonstrate the feasibility of using ANNs rather than human roleplayers to control portions of a battle simulation. ROLEPLAYER demonstrates the interaction between several friendly (Blue) battalions, controlled by a human operator and several opposing (Red) battalions controlled primarily by ANNs. The model uses six neural nets: three at the battalion level (refer to Fig. 2); two at the company level (refer to Fig. 3); and one at the platoon level (refer to Fig. 4). Each net receives a number of input conditions, which are listed above each decision box, and produces a single outcome decision value. Each input condition and the output decision are described as a set of states (not shown on these figures). Each condition may assume one state, or none, in the set. The specified state defines the neural activation value for its condition. For example, the Enemy Move State condition, which is an input to all three neural nets, can assume one of the States: Marching, Attacking, Halted, Defending and Withdrawing. The ROLEPLAYER model provides state values for these conditions through conventionally-coded rules and algorithms.
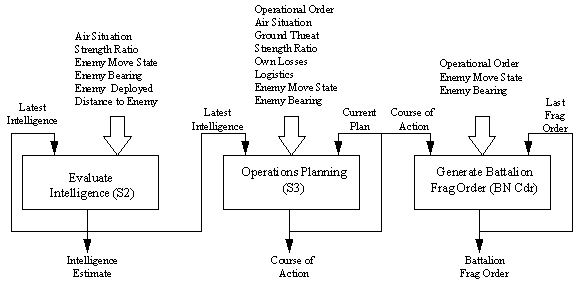
Fig 2. Roleplayer battalion decision structure
The Evaluate Intelligence neural net provides an overall intelligence estimate of the enemy based on observations encoded in its input conditions. This network executes periodically, once every five minutes, to produce a current assessment. It also can respond to events indicating sudden changes in the tactical situation. The net emulates the tactical situation evaluation activity of the Battalion’s Intelligence Officer (S2). The appropriate subject matter expert to train this net would be an actual battalion S2. Table 1 shows the conditions and states of this neural net. The first column defines the conditions (input “pools”) and all columns to the right describe the possible states that each condition can assume. The top rows are the set of input conditions and the bottom row is the output decision. Several conditions, such as Air Situation and Strength Ratio have arbitrary measures—although in terms which a human decision maker is likely to consider. The ROLEPLAYER model is able to translate actual metrics into these categories, but to improve user understandability it is probably better to define Strength Ratio using states such as “Less than 1:2” (Low) and “Greater than 2:1” (High). Note that the intelligence estimate, “Intel Estimate”, also has a feedback path into the Evaluate Intelligence neural net and is an input into the Operational Planning neural net. The input into the Operational Planning net represents communications from the S2 to the Operations Officer (S3). The feedback of earlier recommendations into the net itself represents the fact that situation evaluation is not likely to change immediately, without considering previous estimates. Conditions that are output from one neural net and input into another net must have identical sets of possible states.
The battalion Operations Planning neural net receives the Operational Order and Fragmentary Operational Orders (Frag Orders) from higher headquarters (refer to Table 2). It considers this order along with other conditions including the Intelligence Estimate output from the Evaluate Intelligence neural net and determines what course of action to take at the battalion level. This network executes periodically, once every five minutes or in response critical tactical condition changes, to produce a current course of action. Depending on the input conditions and the encoded training, the ANN will recommend to continue carrying out the current mission, or to follow another, more appropriate, course of action. It essentially emulates the immediate operations re-planning and course of action determination activities of the Battalion Operations Officer (S3). The optimal subject matter expert to train this net would be an actual S3 for Blue forces, or an Intelligence officer familiar with enemy doctrine, equipment, and tactics for the Opposing Force (OPFOR). This net also considers its last recommendation as one of the inputs, and provides its recommendation to the battalion Fragmentary Operational Order (Frag Order) net.
Condition
Last Estimate
Air Situation
Strength Ratio
Enemy Move State
Enemy Bearing
Enemy Deployed
Distance to Enemy
Intelligence Estimate
States
No Threat
Enemy Superior
High
March
Ahead
Yes
Near
No Threat
Distant Threat
Parity
Equal
Attack
Flank
No
Far
Distant Threat
Enemy in Defense
Friendly Superior
Low
Halt
Behind
None
Enemy in Defense
Impending Attack
Defending
Impending Attack
Surrounded
Withdrawing
Surrounded
Rear Threat
Rear Threat
Flank Threat
Flank Threat
Table 1. Roleplayer evaluates intelligence neural net structure
Flank Threat
Defending
Abandon Mission
Surrounded
Disengaging
Abandon Mission
Seize Objective
Defend Position
Impending Attack
Tactical Move
Surround
Defend Position
Reconnoiter
Friendly Superior
Attack
Enemy in Defense
None
Low
High
Red
Halt
Behind
Attack
Defend
Parity
Reduce Threat
Distant Threat
Far
Equal
Medium
Amber
Attack
Flank
Reduce Threat
States
Road March
Enemy Superior
Continue Mission
No Threat
Near
High
Low
Green
March
Ahead
Continue Mission
Condition
Operation Order
Air Situation
Current Plan
Latest Intelligence
Ground Threat
Strength Ratio
Own Losses
Logistics
Enemy Move State
Enemy Bearing
Course of Action
Rear Threat
Table 2. Roleplayer battalion operations neural net structure
The battalion Frag Order neural network is responsible for deciding what Frag Orders the battalion will send to the company commanders under its command. Table 3 shows the input conditions that this net considers and its output decision in the last row. It executes periodically, once every five minutes, or in response to tactical emergencies, to produce a new Frag Order. It considers the Course of Action decision, produced by the Battalion Operations ANN, and also its previously issued Frag Order as a feedback from its previous execution. The most common outcome from this ANN is a “Continue” decision, which means that there is no change to the order that each company is being directed to carry out. Again, the decision it actually makes depends on how the network was trained. You may observe that the input conditions for each of these neural nets appear to be arbitrary. What is included as input conditions to a neural net is a decision that the simulation designer must make jointly with military subject area experts.
Disengage
Disengage
Condition
Operation Order
Last Frag Issued
Course of Action
Enemy Move State
Enemy Bearing
Trag Order
States
Road March
Continue
Continue Mission
March
Ahead
Continue
Defend
Halt
Reduce Threat
Attack
Flank
Halt
Reconnoiter
March
Attack
Halt
Behind
Attack
Seize Objective
Attack
Defend Position
Tactical Move
Surrounded
Attack
Defend Position
Abandon Mission
Disengaging
Defend Position
Withdraw Fighting
Defending
Withdraw Fighting
Table 3. Roleplayer task force frag order neural net structure
The ROLEPLAYER Company Command and Control functions include two neural nets: one issues Frag Orders to the platoons under the company’s command and the other issues requests for fire support when the need exists (refer to Fig. 3). The Company Frag Order neural network is responsible for deciding what Frag Orders the company commander will issue to his platoons. It emulates the Company Commander’s function in immediate tactical control of the subordinate platoons (refer to Table 4). It executes approximately once every two minutes, or in response to tactical emergencies, to produce a new Frag Order. It considers the battalion Frag Order issued by the Task Force commander and will generally issue a corresponding Frag Order to the platoons unless its training instructs it to do otherwise, depending on the current input conditions. The Roleplayer simulation evaluates conditions, such as Strength Ratio, as relative to the strength of the opposing enemy company as it is currently perceived in the simulation. A “Continue” outcome results in the platoon continuing its current activity. If the company has issued a new Frag Order, then the platoon neural net will generally decide to follow that order unless other conditions mandate a different decision.
The Company Fire Support Request neural net evaluates the need for external support (refer to Table 5). The support that may be received within the capabilities of ROLEPLAYER is either indirect fire, or Air Support. It emulates a Company Fire Support Team’s functions. Its decision, “Action” will be either that no fire support is currently needed, or that it is. If support is requested, it causes ROLEPLAYER to pass the fire support request to an additional artificial neural net (not shown), the Battalion’s Fire Support Coordination net (FSC net). The FSC net will, depending on available assets and on the Battalion level evaluation of the tactical situation, either grant or disapprove the request. If the request is granted, the FSC net also decides the allocation of appropriate assets (indirect fire or air support) and sets the execution of the support activity into motion. Time delays between approval of support requests and actual support are due to factors that may be directly a part of the simulation (such as the movement of aircraft), and factors indirectly included in the simulation (additional C3 delays, time required to shift fires, take-off time of ready aircraft, etc.).
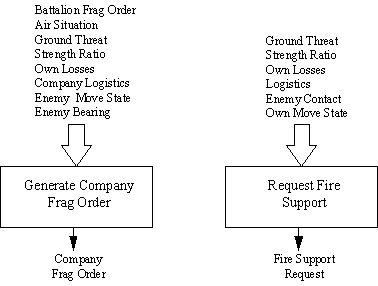
Figure 3. ROLEPLAYER company decision structure
The Platoon Frag Order neural network (Refer to Fig. 4) is responsible for deciding what Frag Orders the platoon leader will issue. It emulates the platoon leader’s immediate tactical control function. It executes approximately once each minute to produce a new Frag Order. Table 6 shows the input conditions for this neural net. The bottom row shows the output decision. A “Continue” outcome results in the platoon continuing its current activity. If the company has issued a new Frag Order, then the platoon neural net will generally decide to follow that order unless other conditions mandate a different decision. When the platoon issues the order, all units in the platoon will follow that order, unless immobilized or destroyed.
Disengage
Disengage
Condition
Frag Order Received
Air Situation
Ground Threat
Strength Ratio
Own Losses
Logistics
Enemy Move State
Enemy Bearing
Action
States
Continue
Enemy Superior
Near
High
Low
Green
March
Ahead
Continue
Halt
Parity
Far
Equal
Medium
Amber
Attack
Left Ahead
Halt
March
Friendly Superior
None
Low
High
Red
Halt
Right Ahead
March
Attack
Defending
Left Flank
Attack
Defend Position
Withdrawing
Right Flank
Defend Position
Withdraw Fighting
Behind
Withdraw Fighting
Multiple Frags
Table 4. Roleplayer company frag order neural net structure
None
Low
High
Red
Other
Beyond 800 meters
Equal
Medium
Amber
No
Defend
Call Support
States
Within 800 meters
High
Low
Green
Yes
Attack
No Support Required
Condition
Ground Threat
Strength Ratio
Own Losses
Logistics
In Contact
Own Move State
Action
Table 5. Roleplayer company fire support request neural net
Neural Net Application to EAGLE Decision Model
Currently PSI is engaged in adapting neural nets to make some low-level decisions in the EAGLE battle simulation. EAGLE is a corps/division-level combat model with resolution to the maneuver battalion, intended for use as a combat development analysis tool. At least two candidate areas for making neural net decisions have been identified. One is planning the current operational activity and the other is determining when to transition to the next objective.
Planning and Ordering requires assessing the current situation and possible options for a new plan, then issuing new orders to implement the new plan. At the Division/Corps level, planning/re-planning requires determining a sequence of phased operations, and within each phase, selecting multiple objectives and tasks for the various units at lower echelons. At the battalion level (the lowest level in EAGLE), each unit only carries out the orders passed down to it. However battalions should have the latitude to replan to the extent that they can digress from those orders, when required, for self defense or when a different course of action would be more effective in attaining its objective. At the division and brigade levels, re-planning consists of elaborating on division orders to the extent that they break broad orders into more detailed tasks and objectives that can be assigned to lower level units.
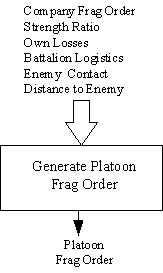
Figure 4. ROLEPLAYER platoon decision structure
Multiple Frag
Withdraw Fighting
Withdraw Fighting
Defend Position
Defend Position
Attack
Attack
March
Low
High
Red
March
Halt
Equal
Medium
Amber
No
No
Halt
States
Continue
High
Low
Green
Yes
Yes
Continue
Condition
Frag Order Received
Strength Ratio
Own Losses
Logistics
In Contact
Enemy Within 1000 meters
Action Decision
Disengage
Disengage
Table 6. Roleplayer platoon frag order neural net structure
The EAGLE simulation uses more decision variables at the battalion level than a single Neural Net should process within our highly anthropomorphic model (because the human trainer cannot easily consider all of them at the same time). To simplify processing it is advisable to subdivide the decision process into several neural net layers (refer to Fig. 5). The top layer performs basic evaluations of internal and external conditions such as the unit’s current effectiveness, the current threat level, the current combat intensity and the current state of the mission. These nets feed their decisions about these conditions into a lower level net which considers them along with the unit’s current operational activity, self intention and assigned task to arrive at a decision about what operational activity it will continue to pursue.
At the battalion level, EAGLE maintains a number of data base items that pertain to the current logistics state of each battalion. The Self Evaluation neural net groups these items together to perform an evaluation which measures the overall effectiveness of the unit and its currently ability to continue with its mission.
The Combat Evaluation neural net determines the level of combat currently in progress, if any. It measures the combat level as: No Engagement, Light Engagement, Medium Engagement or Heavy Engagement. The Threat Evaluation and Mission Evaluation nets also consider the outcome of this net as part of its decision input.
The Threat Evaluation neural net assesses the implied state of the threat. This net considers information such as the relative position of the enemy and the enemy’s activity and arrives at an overall assessment of the threat. The threat level introduces the probability of an engagement if the unit continues to pursue its current mission.

Figure 5. EAGLE evaluate operational activity decision structure
The Mission Evaluation neural net assesses the current state of the unit’s mission implied by conditions such as the extent to which the unit is currently engaged with the enemy, the state of the mission relative to its objective, and the unit’s current activity. This net decides what the overall state of the mission is. The second layer of the network produces the primary output of the decision structure: the decision about what to pursue as the operational activity. This neural net receives inputs from the Combat Evaluation, Threat Evaluation, Mission Evaluation and Self Evaluation first-layer neural nets and the additional variables Operational Activity (providing feedback from prior decisions), Move Status, Self Intent and Task. It is assumes that Task provides the current Operation or Frag order from the higher-level command. This net’s output is an Operational Activity, which determines what activity the unit will pursue next.
Another function required by the EAGLE model is deciding when to transition to a new objective. An Evaluate Next Objective neural net determines whether a unit needs to transition from its assigned activity to another activity (refer to Fig. 6). Reasons for the transition include the need for better self defense and better methods for achieving the objective. Input conditions include the current operational activity, threat level, unit effectiveness, combat intensity and mission status evaluations made by the Evaluate Operational Activity Decision Structure. This net determines whether the unit should transition to a new objective and returns the name of the function that will determine the specific objective. Possible outcomes include: Continue with Current Objective (i.e. no change), Get next planned objective, Get final objective, Get hasty battle position, Attack greatest threat enemy, Get break contact objective, and Get objective closest friendly reserve Ground Mobile Unit.

Figure 6. EAGLE evaluate next objective decision structure
Defining and Training LINIAC Neural Nets
Before a neural net can function correctly it must be trained. Training establishes the “neural” connection values (weights) between the input and output vector elements of the network. A LINIAC ANN retains its training by saving essential information in an external text file. This file is useful both for initializing an instance of a neural net in a client application or for re-entering into the training program for review or additional training. Client initialization occurs by loading the connection matrix information from the file into a data store that the ANN maintains in the client application. In addition to the connection matrix, this file contains information to enable the neural net engine to map input and output state values to the correct locations in the input and output vectors. It also contains the examples used for training, which can be useful for later review or retraining.
Pathfinder Systems has developed the Course of Action Planner (COAP) program as a graphic-based interactive program to provide the ability to define and train neural nets easily. One view provides the net definition capability, while a second view provides the training capability. Various dialog boxes appear on each screen to provide options for a complete training scenario. COAP performs two primary functions; it enables the user to define the set of Conditions and States that comprise the network and it enables the user to train or evaluate the neural net. Training consists of providing a set of examples and commanding COAP to learn the behavior specified in those examples.
Defining a Neural Net
The COAP Definition window provides two basic dialogue boxes (refer to Fig. 7). The box on the left enables the user to define the set of conditions that the neural net will consider and the rightmost box enables the user to specify the states that each condition may assume. Conditions and States use symbolic names, which are used consistently throughout the definition and training process and for the actual execution of the neural net in its application.
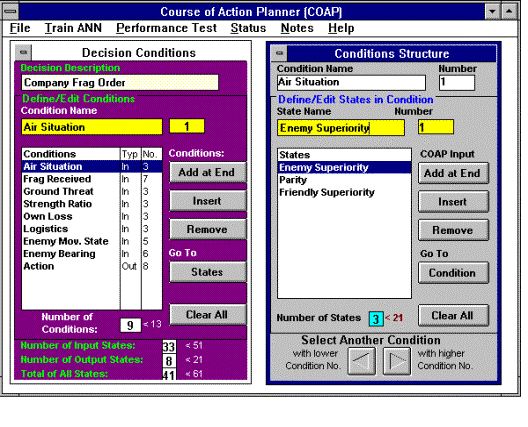
Figure 7. COAP neural net definition interface
These symbolic names define the conditions and their states using terminology that is natural for the user. It is the job of the application programmer to adapt the neural net interface to the terminology that the net designer has supplied; however, the LINIAC input file includes all symbolic names used by the neural net, which simplifies this task considerably. Of course, care must be taken to ensure that the neural net uses information that the application can conveniently provide and that the outcome states are also meaningful to it. The user has the freedom to add and modify Conditions and States until satisfied that the set represents the required decision variables adequately. Once training has begun, it is possible to change the symbolic names; however, adding or deleting conditions or states negates all previous training and requires that training be restarted from the beginning. Once defined, COAP maintains the set of state and condition names, training examples and connection values (the training) in the text file. This file must be imported into the using application to initialize the connection matrix.
Neural Net Training
The COAP Training window provides Teaching and Review modes (refer to Fig. 8). Teaching mode provides on-line (Direct Drill) and background (Homework) modes of operation. Training progresses by defining a set of input values and requesting a decision from the network by clicking the “Show Results” button. The trainer may accept the decision that the network returns, but if the decision is not desirable, the trainer specifies the correct decision and instructs the neural net to “learn” the new behavior. The user may specify that learning occur on-line or it may be queued as “homework” for batch processing later. On-line training usually requires a few seconds to several minutes per example to process. The length of time depends primarily on the number of examples already incorporated in the network and how closely a new example replicates a previously learned example. Since thirty to fifty examples may be adequate to provide acceptable output decisions over a wide range of input conditions, a user may be able to train a network within a period of several hours. On rare occasions, it is possible for two training examples to represent patterns that are inconsistent so that the training algorithm cannot resolve the differences (i.e. the back propagation algorithm cannot converge to a solution). If this happens, it is necessary to review the training examples, eliminate the anomalies and retrain the network.
The Review mode, not shown in Fig. 8, enables the trainer to review all previous training. Since COAP preserves all training examples in its external text file, it is possible to break training into multiple sessions. Thus the trainer may review previous training in a later session for validation or to avoid redundant input. This also enables a user to retrain or provide additional training for a neural net if the initial training proves to be incorrect or inadequate for the intended application.
COAP configures the Training and Evaluation Window to show all input Conditions in the upper left part of the window. Beneath each Condition name, COAP shows all States that define that Condition. During the training session, the user selects a state for each condition for a specific training example, then selects the Show Results function. COAP responds by displaying the corresponding output state that it has currently “memorized”. The trainer may respond one of three ways: accept the result if is consistent with the desired results, reject the outcome or disregard it. If the trainer rejects the outcome, COAP provides the opportunity to specify the correct response and then prompts the trainer to initiate learning. Learning occurs by adjusting the connection matrix values so that the net will produce the desired outcome for the given stimulus without violating previously learned behavior. Because neural nets can extrapolate previously learned patterns to match similar input patterns, it is not necessary for the trainer to present many similar patterns to train the network effectively. This ability to extrapolate reduces training time considerably and makes the neural net a very cost-effective tool.

Figure 8. COAP neural net training interface
Another COAP function available in Review mode is the Performance Test option. This option performs a number of sequential executions of the neural net and displays the average execution time to the user. The average time will vary from a few milliseconds to a few tens of milliseconds on a 33 MHz 80486 PC, depending on the complexity of the neural net. This contrasts favorably with many other current neural net implementations, which require substantial computation times. The speed of LINIAC’s computation cycle makes it quite attractive for many applications since it can typically perform one to several orders of magnitude faster than comparable rule-based or algorithmic implementations.
Conclusion
This paper has presented a practical approach for using artificial neural nets to perform automated decision making in the context of combat simulations. Neural nets can be much easier to design and implement than comparable algorithms or rule bases. A single neural net engine can function as a server for an arbitrary number of neural nets. The “code” required to execute a neural net can be encapsulated in an external data file, including both the connection matrix and the condition/state definitions for the input and output vectors. Because of this external encoding, the behavior of a client can be modified simply by substituting a differently trained ANN without changing source code. This greatly reduces the amount of time and the expense required to design, implement and maintain decision logic/code for automated forces. In simulations this provides essential flexibility because the behavior of automated forces may need to change to reflect different scenarios. This also makes it possible to replace neural nets whose initial training may contain deficiencies.
Because it is possible to train neural nets using a relatively simple graphic interface, it is possible to have “experts” train them quickly and directly without requiring intermediate technical personnel who may inadvertently introduce personal biases into the decision base. This user interface also provides the capability to review the training and behavior of a neural net and thus provides a first level validation for the behavior of the net. Neural nets reflect their training examples very faithfully and avoid unnecessary errors caused by coding anomalies. They are also very good at reflecting the behavior extrapolating learned examples to cover conditions for which they have no discrete training, which greatly reduces the time that experts must spend in training them. The LINIAC neural net implementation possesses a very fast execution speed, and even a structure of multiple neural nets operating sequentially to produce a single decision may easily out-perform a comparable algorithmic or rule-based implementation. Finally, PSI has verified their performance, reliability and accuracy in several demonstration projects.