PATHFINDER SYSTEMS, INC.
Simulación de campo de batalla
Comando y control de simulación de campo de batalla automatizado mediante redes neuronales artificiales
Stewart H. Jones, Ivan J. Jaszlics y Sheila L. Jaszlics
Pathfinder Systems, Inc.
Lakewood, Colorado 80228
Abstracto
Las simulaciones de batalla interactivas distribuidas contemporáneas son cada vez más grandes y complejas y, por lo tanto, difíciles de administrar. El éxito de los proyectos futuros dependerá, en parte, de la capacidad de gestionar aspectos del mando y control de las fuerzas de forma automatizada y altamente predecible. La inteligencia artificial en general y las redes neuronales artificiales en particular ofrecen atractivos mecanismos para automatizar el comando y el control. Pathfinder Systems ha desarrollado la Red Neural Artificial del Modelo Linear Interactive Activation and Competition (LINIAC), un modelo orientado a objetos de alta velocidad, para su uso en varias simulaciones de batalla y ha demostrado que esta es una aplicación factible de esta tecnología. LINIAC es muy adecuado para proporcionar funciones de gestión de batalla y control de decisiones automatizadas para una variedad de simulaciones constructivas del campo de batalla. Emula las funciones de toma de decisiones de los comandantes de unidades tácticas y su personal, representadas por los jugadores / controladores en los ejercicios del puesto de mando. LINIAC utiliza un diseño orientado a objetos que reconoce un patrón de situación y proporciona un resultado correspondiente en el lapso de varias o varias decenas de milisegundos. Una ventaja clave de LINIAC es que su entrenamiento está codificado e inicializado desde una estructura de datos externa en lugar de codificado como bases de reglas o algoritmos. Por lo tanto, es posible reemplazar o reentrenar las redes LINIAC fácilmente para cumplir con los nuevos requisitos sin modificar el código. La capacitación de LINIAC utiliza una interfaz gráfica para que los capacitadores no necesiten capacitación en lenguaje informático o habilidades informáticas especiales. Los expertos con conocimientos especializados pueden incorporar sus conocimientos en redes neuronales directamente sin necesidad de los servicios de un ingeniero del conocimiento. Por lo general, un capacitador puede ingresar dos o tres docenas de ejemplos de capacitación por hora. Pathfinder Systems ha demostrado la capacidad de usar redes neuronales artificiales LINIAC en varios programas de simulación de batalla para proporcionar comando y control automatizados de al menos parte de las fuerzas en la simulación. Los resultados de estos proyectos han demostrado que el uso de redes neuronales LINIAC puede emular con éxito el elemento de toma de decisiones humanas en simulaciones de batalla con resultados que son equivalentes a los que los jugadores de roles humanos y las bases de reglas automatizadas pueden proporcionar.
Introducción
Una consideración fundamental en el diseño de simulaciones de campo de batalla es que se acerquen al realismo con la mayor fidelidad posible. Una dificultad para simular el mando y control en el campo de batalla es replicar el proceso de toma de decisiones en el que se basa. El propósito de muchas simulaciones es entrenar a una parte de su audiencia para que tome decisiones de batalla aceptables. Aquí es apropiado que los operadores humanos realicen funciones de toma de decisiones. Sin embargo, el uso de jugadores de rol humanos para tomar decisiones para las Fuerzas Opuestas, o fuerzas adyacentes y traseras amigas puede ser contraproducente y el comando y control automatizados puede ser muy deseable. Para proporcionar dicha automatización, muchas simulaciones actuales se basan en gran medida en algoritmos de decisión y bases de reglas junto con jugadores de roles humanos para proporcionar el elemento humano. Pueden surgir problemas porque los algoritmos y las bases de reglas pueden no estar lo suficientemente libres de errores y los recursos de los jugadores de roles humanos a veces son difíciles de controlar. La automatización que utiliza algoritmos y bases de reglas también puede carecer de la flexibilidad suficiente para cumplir con los requisitos de escenarios cambiantes sin una programación elaborada. Las redes neuronales artificiales (ANN) ofrecen una alternativa rentable a los algoritmos y las bases de reglas para generar o replicar la toma de decisiones humana. Las ANN son eficaces porque se basan en ejemplos, en lugar de implementaciones codificadas.
Este documento describe un enfoque que Pathfinder Systems, Inc. (PSI) ha adoptado para aplicar RNA para automatizar el Comando y Control para simulaciones militares. PSI ha desarrollado el modelo de red neuronal LINIAC para la emulación de decisiones de comando y control. Se ha utilizado para demostraciones con la Simulación de Batalla de Brigada / Batallón (BBS), dentro del proyecto de Interoperación BBS-SIMNET para generar decisiones para Fuerzas Semiautomatizadas SIMNET, y en ROLEPLAYER, una simulación de campo de batalla muy simple, que demuestra un uso práctico de Redes neuronales LINIAC a nivel de pelotón, compañía y batallón. Otro ejemplo, actualmente en desarrollo por PSI y MITRE Corporation, es la aplicación de ANN al modelo de simulación de batalla EAGLE. Actualmente, la simulación EAGLE se basa en gran medida en decisiones basadas en reglas. Este proyecto pretende demostrar la viabilidad de reemplazar las bases de reglas en el nivel más bajo de comando y control en una simulación compleja con ANN.
La necesidad de un comando y control de IA flexible
Existen algunas dificultades obvias con el uso de algoritmos y bases de reglas para replicar la toma de decisiones humana. Por lo general, están codificados de forma rígida y son difíciles de cambiar si cambian las necesidades de la simulación. Los recientes desarrollos militares globales, como la disolución de las fuerzas soviéticas y del Bloque del Este y el surgimiento de las fuerzas militares del tercer mundo, han cambiado los requisitos de mando y control para las simulaciones de batalla. Hoy deben ser lo suficientemente flexibles para adaptarse a una variedad de doctrinas militares y modos de operación, que a menudo requieren una rápida reconfiguración. Si es necesario implementar algoritmos y bases de reglas utilizando lenguajes de entrada de datos o programación sintácticamente rígidos, su desarrollo requiere que los técnicos de programación traduzcan los requisitos de comando y control a la sintaxis del lenguaje apropiado. Los pasos necesarios para traducir el conocimiento de los expertos en una sintaxis formalizada introducen la posibilidad de mala comunicación y malentendidos, que pueden resultar en errores de programa. Incluso cuando existe una buena comprensión, los errores lógicos se pueden generar inadvertidamente. Se requiere una cantidad significativa de pruebas para detectar y eliminar tales errores. Finalmente, las bases de reglas y los algoritmos generalmente deben tener en cuenta todas las posibles contingencias al analizar un problema, de modo que las condiciones no contabilizadas no generen resultados no deseados en la simulación. Se necesita un esfuerzo de ingeniería significativo para garantizar que todas las situaciones razonables estén representadas en el código.
El uso de redes neuronales artificiales para el comando y control automatizados puede superar muchas de estas limitaciones. Las ANN se pueden implementar como una clase de objeto con una interfaz estándar y métodos de decisión. Una simulación puede entonces crear muchos objetos de decisión de esa clase, cada uno con su entorno único que consiste en información de entrada y una "matriz de conexión" que encapsula el comportamiento de una RNA en particular. El método de decisión es un proceso matemático relativamente simple que es válido para una amplia variedad de aplicaciones de decisión. Un objeto ANN bien diseñado puede acomodar cualquier base de decisión compatible y replicar fielmente el razonamiento cognitivo con el que ha sido entrenado.
Es posible diseñar métodos de capacitación para RNA utilizando técnicas de interfaz gráfica estándar que no requieren ninguna experiencia en programación por parte del capacitador, de modo que los expertos en conocimiento puedan capacitarlos directamente sin tener que depender de un intérprete técnico. Los expertos pueden aprender de forma rápida, a menudo intuitiva, cómo utilizar estas interfaces para entrenar a las ANN directamente en sesiones que duran solo una hora o dos. Los expertos también pueden definir las variables de comando y control utilizando palabras y frases en inglés que tengan sentido tanto para el capacitador como para la audiencia de capacitación. Al entrenar las RNA, no es necesario proporcionar ejemplos para todas las combinaciones de entrada posibles, como ocurre generalmente con los algoritmos y las bases de reglas. Una red neuronal puede tener de miles a cientos de miles de posibles combinaciones de entrada, pero una pequeña muestra representativa del total es suficiente para un entrenamiento adecuado. Las ANN son muy buenas para extrapolar los ejemplos con los que fueron capacitados para cubrir otros ejemplos similares. La clave para una buena formación, por supuesto, es incluir ejemplos que cubran la gama más amplia posible de condiciones de entrada.
Si una simulación debe poder acomodar múltiples escenarios para reflejar diferentes doctrinas militares o modos de operación, entonces es posible entrenar a las ANN para cada escenario e inicializar los objetos ANN apropiados para el escenario especificado con el comportamiento requerido al iniciar la simulación en lugar de modificar el código de simulación. Esta técnica también se aplica al comando y control automatizados para múltiples escalones. La estructura de decisiones para varios escalones puede ser similar en el sentido de que cada escalón considera el mismo conjunto de condiciones y toma decisiones equivalentes. La única diferencia puede ser que cada escalón puede utilizar un razonamiento diferente para llegar a decisiones comparables. Por lo tanto, es posible aplicar una única estructura de decisión a varios escalones, pero hacer que cada escalón utilice un conjunto de objetos ANN entrenados de forma única para reflejar su razonamiento individual.
Finalmente, es posible entrenar redes neuronales de forma incremental. Si una RNA demuestra un comportamiento inapropiado dentro de una simulación, es posible volver a capacitarla rápidamente. De hecho, la formación a través de escenarios de simulación es un método de formación muy eficaz.
El modelo de competencia y activación interactiva lineal (LINIAC)
Como parte de su investigación sobre el uso de ANN para aplicaciones de comando y control, Pathfinder Systems, Inc. ha desarrollado el Modelo ANN de Competencia y Activación Interactiva Lineal (LINIAC). La Figura 1 ilustra cómo toma decisiones el modelo LINIAC. Cada LINIAC ANN consta de un vector de entrada, que se muestra como flechas que apuntan hacia abajo, un vector de salida, que se muestra como flechas que apuntan a la derecha, y una matriz de conexión. El vector de entrada define un conjunto de condiciones de entrada, donde cada condición puede asumir uno de dos o más estados. El número real de condiciones y estados para una ANN dada es arbitrario, pero no puede cambiar una vez que la ANN ha sido entrenada sin requerir reentrenamiento. En el modelo LINIAC, cada condición puede asumir solo un estado, que se expresa con un valor de 1, mientras que todos los demás estados para esa condición se expresan con un valor de 0 (aunque también son posibles valores numéricos ponderados). El vector de salida LINIAC consta de una condición también con un número arbitrario de estados. Los puntos negros, que se muestran en la intersección de cada flecha horizontal y vertical, representan las conexiones neuronales entre los elementos vectoriales de entrada y salida y el tamaño de cada punto sugiere la fuerza relativa o el "peso" de la conexión. El peso determina la fuerza con la que cada estado de entrada influye en el estado correspondiente del vector de salida. Una decisión LINIAC siempre se selecciona como el estado de salida con el mayor valor acumulativo. La clave para el funcionamiento exitoso de LINIAC es establecer los valores de la matriz de conexión durante el entrenamiento para que un patrón de entrada dado siempre produzca el resultado que el entrenador ha especificado.

Fig 1. Concepto de red neuronal artificial LINIAC
Aplicación de red neuronal para comando y control automatizados
Hay muchas formas de aplicar redes neuronales al comando y control automatizados, que van desde redes neuronales únicas hasta estructuras de decisión muy complejas compuestas por capas de redes neuronales. La discusión restante se enfocará en los varios ejemplos / modelos desarrollados por o en desarrollo por PSI. Una ventaja del enfoque de la red neuronal es la capacidad de agrupar decisiones relativamente simples en una estructura de decisiones compleja. Esto es análogo a la forma en que normalmente se toman las decisiones organizativas complejas. Otra ventaja es que este enfoque permite al diseñador dividir decisiones complejas en componentes simples que son mucho más fáciles de diseñar, comprender y entrenar.
El éxito o el fracaso del uso de ANN dependerá en gran medida de la validez del diseño del modelo de decisión. El modelo que se presenta a continuación es uno de los muchos conceptos potenciales. El valor de este enfoque es que se pueden diseñar, rediseñar y reconectar elementos simples en una estructura que represente con precisión el proceso de toma de decisiones de una unidad militar real. Una estructura de decisión viable probablemente será un híbrido de algoritmos, reglas y redes neuronales trabajando juntos. Se necesitan algoritmos para transformar los datos de simulación en tipos de datos (es decir, variables de decisión) que sean apropiados para la entrada en las RNA de la estructura de decisión. No todos los tipos de decisiones se implementan mejor a través de redes neuronales; cuando el número de posibilidades de entrada y el número de resultados es pequeño, las reglas algorítmicas suelen ser una mejor opción. Tendemos a usar redes neuronales cuando las posibles combinaciones de las entradas, incluso si no son borrosas, pueden llegar a miles o cientos de miles.
El entrenamiento de una red es casi trivial si lo realiza un experto en la materia. Lo que es muy importante es determinar la estructura de decisión general para una actividad representada por una ANN (esto puede ser, por ejemplo, un C2 humano específico función, como "armadura BN S2 — evaluar la situación actual"). Es de esperar que el diseño de una estructura de decisión se someta a un proceso evolutivo que mejorará su realismo. Los elementos principales de un diseño incluyen el conjunto de decisiones (las ANN) que la simulación requiere en cada punto de comando y control, la estructura de cada proceso de decisión (las condiciones y estados de cada ANN), las conexiones a la base de datos de simulación y las interconexiones entre las RNA seleccionadas. Inicialmente, la forma en que se capacita a las RNA individuales es de menor importancia, ya que la capacitación o reentrenamiento puede ocurrir después de la implementación.
El modelo de jugador de rol
PSI desarrolló originalmente el modelo ROLEPLAYER para demostrar la viabilidad de usar ANN en lugar de jugadores de rol humanos para controlar partes de una simulación de batalla. ROLEPLAYER demuestra la interacción entre varios batallones amigos (azules), controlados por un operador humano y varios batallones opuestos (rojos) controlados principalmente por ANN. El modelo utiliza seis redes neuronales: tres a nivel de batallón (consulte la Fig. 2); dos a nivel de empresa (consulte la Fig. 3); y uno a nivel de pelotón (consulte la Fig. 4). Cada red recibe una serie de condiciones de entrada, que se enumeran encima de cada cuadro de decisión, y produce un valor de decisión de resultado único. Cada condición de entrada y la decisión de salida se describen como un conjunto de estados (no se muestran en estas figuras). Cada condición puede asumir un estado, o ninguno, en el conjunto. El estado especificado define el valor de activación neuronal para su condición. Por ejemplo, la condición Enemy Move State, que es una entrada para las tres redes neuronales, puede asumir uno de los estados: Marchando, Atacando, Detenido, Defendiendo y Retirándose. El modelo ROLEPLAYER proporciona valores de estado para estas condiciones mediante reglas y algoritmos codificados de forma convencional.
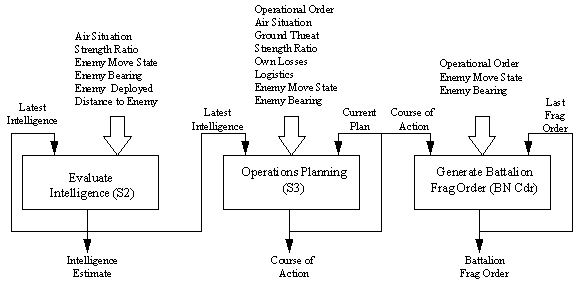
Fig 2. Estructura de decisiones del batallón de jugadores de rol
La red neuronal Evaluate Intelligence proporciona una estimación de inteligencia general del enemigo basada en observaciones codificadas en sus condiciones de entrada. Esta red se ejecuta periódicamente, una vez cada cinco minutos, para producir una evaluación actual. También puede responder a eventos que indiquen cambios repentinos en la situación táctica. La red emula la actividad de evaluación de situación táctica del Oficial de Inteligencia del Batallón (S2). El experto en la materia apropiado para entrenar esta red sería un batallón S2 real. La Tabla 1 muestra las condiciones y estados de esta red neuronal. La primera columna define las condiciones ("grupos" de entrada) y todas las columnas a la derecha describen los posibles estados que puede asumir cada condición. Las filas superiores son el conjunto de condiciones de entrada y la fila inferior es la decisión de salida. Varias condiciones, como la situación del aire y el índice de fuerza, tienen medidas arbitrarias, aunque en términos que es probable que considere un tomador de decisiones humano. El modelo ROLEPLAYER puede traducir las métricas reales en estas categorías, pero para mejorar la comprensión del usuario, probablemente sea mejor definir el índice de fuerza utilizando estados como "Menos de 1: 2" (bajo) y "Mayor que 2: 1" (alto ). Tenga en cuenta que la estimación de inteligencia, "Estimación de Intel", también tiene una ruta de retroalimentación en la red neuronal Evaluate Intelligence y es una entrada en la red neuronal de planificación operativa. La entrada a la red de planificación operativa representa las comunicaciones del S2 al oficial de operaciones (S3). La retroalimentación de recomendaciones anteriores en la propia red representa el hecho de que no es probable que la evaluación de la situación cambie de inmediato, sin considerar estimaciones anteriores. Las condiciones que salen de una red neuronal y entran en otra red deben tener conjuntos idénticos de estados posibles.
La red neuronal de Planificación de Operaciones del batallón recibe la Orden Operacional y las Órdenes Operacionales Fragmentarias (Órdenes Frag) de los cuarteles generales superiores (consulte la Tabla 2). Considera este orden junto con otras condiciones, incluida la salida de Estimación de inteligencia de la red neuronal Evaluar inteligencia y determina qué curso de acción tomar a nivel de batallón. Esta red se ejecuta periódicamente, una vez cada cinco minutos o en respuesta a cambios de condiciones tácticas críticas, para producir un curso de acción actual. Dependiendo de las condiciones de entrada y del adiestramiento codificado, la ANN recomendará continuar con la misión actual, o seguir otro curso de acción más adecuado. Básicamente, emula las actividades inmediatas de reprogramación de operaciones y determinación del curso de acción del Oficial de Operaciones del Batallón (S3). El experto en la materia óptimo para entrenar esta red sería un S3 real para las fuerzas azules, o un oficial de inteligencia familiarizado con la doctrina, el equipo y las tácticas enemigas para la Fuerza Opuesta (OPFOR). Esta red también considera su última recomendación como uno de los insumos, y proporciona su recomendación a la red del Batallón Orden Operativa Fragmentaria (Orden Frag).
Condición
Última estimación
Situación del aire
Relación de fuerza
Estado de movimiento enemigo
Teniendo enemigo
Enemigo desplegado
Distancia al enemigo
Estimación de inteligencia
Estados
No hay amenaza
Superior enemigo
Elevado
marcha
Adelante
sí
Cerca
No hay amenaza
Amenaza distante
Paridad
Igual
Ataque
Flanco
No
Lejos
Amenaza distante
Enemigo en defensa
Superior amable
Bajo
Detener
Detrás
Ninguno
Enemigo en defensa
Ataque inminente
Defendiendo
Ataque inminente
Rodeado
Retirar
Rodeado
Amenaza trasera
Amenaza trasera
Amenaza de flanco
Amenaza de flanco
Tabla 1. El jugador de rol evalúa la estructura de la red neuronal de inteligencia
Amenaza de flanco
Defendiendo
Misión de abandono
Surroun ded
Desengancharse
Misión de abandono
Aprovechar el objetivo
Defender posición
Ataque inminente
Movimiento táctico
Rodear
Defender posición
Reconocer el terreno
Superior amable
Ataque
Enemigo en defensa
Ninguno
Bajo
Elevado
rojo
Detener
Detrás
Ataque
Defender
Paridad
Reducir la amenaza
Amenaza distante
Lejos
Igual
Medio
Ámbar
Ataque
Flanco
Reducir la amenaza
Estados
Marcha por carretera
Superior enemigo
Continuar misión
No hay amenaza
Cerca
Elevado
Bajo
Verde
marcha
Adelante
Continuar misión
Condición
Orden de operación
Situación del aire
Plan actual
Inteligencia más reciente
Amenaza terrestre
Relación de fuerza
Pérdidas propias
Logística
Estado de movimiento enemigo
Teniendo enemigo
Curso de acción
Amenaza trasera
Cuadro 2. Estructura de la red neuronal de operaciones del batallón de jugadores de rol
La red neuronal del batallón Frag Order es responsable de decidir qué Frag Orders enviará el batallón a los comandantes de la compañía bajo su mando. La Tabla 3 muestra las condiciones de entrada que esta red considera y su decisión de salida en la última fila. Se ejecuta periódicamente, una vez cada cinco minutos, o en respuesta a emergencias tácticas, para producir una nueva Orden Frag. Considera la decisión de Curso de Acción, producida por el Batallón de Operaciones ANN, y también su Orden Frag emitida previamente como una retroalimentación de su ejecución anterior. El resultado más común de esta RNA es una decisión de “Continuar”, lo que significa que no hay ningún cambio en el orden que cada empresa debe realizar. Una vez más, la decisión que toma realmente depende de cómo se entrenó la red. Puede observar que las condiciones de entrada para cada una de estas redes neuronales parecen ser arbitrarias. Lo que se incluye como condiciones de entrada a una red neuronal es una decisión que el diseñador de la simulación debe tomar junto con los expertos en áreas temáticas militares.
Desacoplar
Desacoplar
Condición
Orden de operación
Último fragmento emitido
Curso de acción
Estado de movimiento enemigo
Teniendo enemigo
Orden de Trag
Estados
Marcha por carretera
Continuar
Continuar misión
marcha
Adelante
Continuar
Defender
Detener
Reducir la amenaza
Ataque
Flanco
Detener
Reconocer el terreno
marcha
Ataque
Detener
Detrás
Ataque
Aprovechar el objetivo
Ataque
Defender posición
Movimiento táctico
Rodeado
Ataque
Defender posición
Misión de abandono
Desengancharse
Defender posición
Retirar la lucha
Defendiendo
Retirar la lucha
Tabla 3. Estructura de la red neuronal del orden de fragmentación del grupo de trabajo de jugadores de rol
Las funciones de Comando y Control de la Compañía de ROLEPLAYER incluyen dos redes neuronales: una emite Órdenes de Frag a los pelotones bajo el mando de la compañía y la otra emite solicitudes de apoyo de fuego cuando existe la necesidad (consulte la Fig. 3). La red neuronal Company Frag Order es responsable de decidir qué Frag Orders emitirá el comandante de la compañía a sus pelotones. Emula la función del Comandante de la Compañía en el control táctico inmediato de los pelotones subordinados (consulte la Tabla 4). Se ejecuta aproximadamente una vez cada dos minutos, o en respuesta a emergencias tácticas, para producir una nueva Orden Frag. Considera la Orden Frag del batallón emitida por el comandante de la Fuerza de Tarea y generalmente emitirá una Orden Frag correspondiente a los pelotones a menos que su entrenamiento le indique lo contrario, dependiendo de las condiciones de entrada actuales. La simulación de Roleplayer evalúa las condiciones, como la relación de fuerza, en relación con la fuerza de la compañía enemiga enemiga tal como se percibe actualmente en la simulación. Un resultado de "Continuar" da como resultado que el pelotón continúe con su actividad actual. Si la compañía ha emitido una nueva Orden de Frag, entonces la red neuronal del pelotón generalmente decidirá seguir esa orden a menos que otras condiciones exijan una decisión diferente.
La red neuronal de solicitud de apoyo contra incendios de la empresa evalúa la necesidad de apoyo externo (consulte la Tabla 5). El apoyo que se puede recibir dentro de las capacidades de ROLEPLAYER es fuego indirecto o apoyo aéreo. Emula las funciones de un equipo de apoyo contra incendios de la empresa. Su decisión, "Acción", será que actualmente no se necesita apoyo de fuego, o que sí lo es. Si se solicita apoyo, hace que el JUGADOR DE PAPEL pase la solicitud de apoyo de fuego a una red neuronal artificial adicional (no se muestra), la red de Coordinación de Apoyo de Fuego del Batallón (red FSC). La red FSC, dependiendo de los activos disponibles y de la evaluación a nivel de Batallón de la situación táctica, otorgará o desaprobará la solicitud. Si se concede la solicitud, la red FSC también decide la asignación de los activos apropiados (fuego indirecto o apoyo aéreo) y pone en marcha la ejecución de la actividad de apoyo. Los retrasos entre la aprobación de las solicitudes de soporte y el soporte real se deben a factores que pueden ser parte directa de la simulación (como el movimiento de la aeronave) y factores incluidos indirectamente en la simulación (retrasos adicionales de C3, tiempo necesario para cambiar los incendios, hora de despegue de la aeronave lista, etc.).
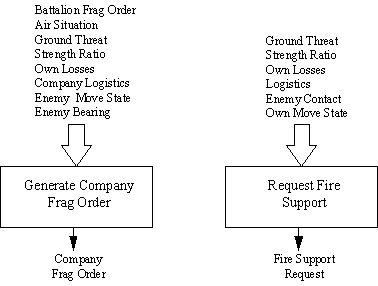
Figura 3. Estructura de decisiones de la empresa ROLEPLAYER
La red neuronal Platoon Frag Order (consulte la Fig. 4) es responsable de decidir qué Frag Orders emitirá el líder del pelotón. Emula la función de control táctico inmediato del líder de pelotón. Se ejecuta aproximadamente una vez por minuto para producir un nuevo Frag Order. La Tabla 6 muestra las condiciones de entrada para esta red neuronal. La fila inferior muestra la decisión de salida. Un resultado de "Continuar" da como resultado que el pelotón continúe con su actividad actual. Si la compañía ha emitido una nueva Orden de Frag, entonces la red neuronal del pelotón generalmente decidirá seguir esa orden a menos que otras condiciones exijan una decisión diferente. Cuando el pelotón emita la orden, todas las unidades del pelotón seguirán ese orden, a menos que sean inmovilizadas o destruidas.
Desacoplar
Desacoplar
Condición
Orden de fragmentación recibida
Situación del aire
Amenaza terrestre
Relación de fuerza
Pérdidas propias
Logística
Estado de movimiento enemigo
Teniendo enemigo
Acción
Estados
Continuar
Superior enemigo
Cerca
Elevado
Bajo
Verde
marcha
Adelante
Continuar
Detener
Paridad
Lejos
Igual
Medio
Ámbar
Ataque
Dejado por delante
Detener
marcha
Superior amable
Ninguno
Bajo
Elevado
rojo
Detener
Adelante
marcha
Ataque
Defendiendo
Flanco Izquierdo
Ataque
Defender posición
Retirar
Flanco derecho
Defender posición
Retirar la lucha
Detrás
Retirar la lucha
Fragmentos múltiples
Tabla 4. Estructura de la red neuronal del orden de fragmentación de la empresa de jugadores de rol
Ninguno
Bajo
Elevado
rojo
Otro
Más allá de 800 metros
Igual
Medio
Ámbar
No
Defender
Soporte de llamada
Estados
Dentro de 800 metros
Elevado
Bajo
Verde
sí
Ataque
No se requiere soporte
Condición
Amenaza terrestre
Relación de fuerza
Pérdidas propias
Logística
En contacto
Estado de movimiento propio
Acción
Tabla 5. Red neuronal de solicitud de soporte contra incendios de la empresa de jugadores de rol
Aplicación de red neuronal al modelo de decisión EAGLE
Actualmente, PSI se dedica a adaptar redes neuronales para tomar algunas decisiones de bajo nivel en la simulación de batalla EAGLE. EAGLE es un modelo de combate a nivel de cuerpo / división con resolución para el batallón de maniobras, destinado a ser utilizado como una herramienta de análisis de desarrollo de combate. Se han identificado al menos dos áreas candidatas para tomar decisiones sobre redes neuronales. Uno es planificar la actividad operativa actual y el otro es determinar cuándo pasar al siguiente objetivo.
La planificación y los pedidos requieren evaluar la situación actual y las posibles opciones para un nuevo plan, luego emitir nuevos pedidos para implementar el nuevo plan. A nivel de División / Cuerpo, la planificación / replanificación requiere determinar una secuencia de operaciones por fases, y dentro de cada fase, seleccionar múltiples objetivos y tareas para las diversas unidades en los escalones inferiores. En el nivel de batallón (el nivel más bajo en EAGLE), cada unidad solo lleva a cabo las órdenes que le son transmitidas. Sin embargo, los batallones deben tener la libertad de volver a planificar en la medida en que puedan desviarse de esas órdenes, cuando sea necesario, para la defensa propia o cuando un curso de acción diferente sería más eficaz para lograr su objetivo. En los niveles de división y brigada, la reprogramación consiste en elaborar las órdenes de división en la medida en que dividen las órdenes generales en tareas y objetivos más detallados que pueden asignarse a unidades de nivel inferior.
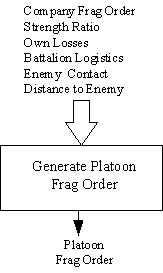
Figura 4. Estructura de decisión del pelotón de ROLEPLAYER
Fragmento múltiple
Retirar la lucha
Retirar la lucha
Defender posición
Defender posición
Ataque
Ataque
marcha
Bajo
Elevado
rojo
marcha
Detener
Igual
Medio
Ámbar
No
No
Detener
Estados
Continuar
Elevado
Bajo
Verde
sí
sí
Continuar
Condición
Orden de fragmentación recibida
Relación de fuerza
Pérdidas propias
Logística
En contacto
Enemigo a menos de 1000 metros
Decisión de acción
Desacoplar
Desacoplar
Tabla 6. Estructura de la red neuronal del orden de fragmentos del pelotón de jugadores de rol
La simulación EAGLE utiliza más variables de decisión a nivel de batallón de las que debería procesar una sola red neuronal dentro de nuestro modelo altamente antropomórfico (porque el entrenador humano no puede considerarlas todas al mismo tiempo). Para simplificar el procesamiento, es aconsejable subdividir el proceso de decisión en varias capas de redes neuronales (consulte la Fig. 5). La capa superior realiza evaluaciones básicas de las condiciones internas y externas, como la efectividad actual de la unidad, el nivel de amenaza actual, la intensidad de combate actual y el estado actual de la misión. Estas redes alimentan sus decisiones sobre estas condiciones en una red de nivel inferior que las considera junto con la actividad operativa actual de la unidad, la intención propia y la tarea asignada para llegar a una decisión sobre qué actividad operativa continuará realizando.
A nivel de batallón, EAGLE mantiene una serie de elementos de la base de datos que pertenecen al estado logístico actual de cada batallón. La red neuronal de autoevaluación agrupa estos elementos para realizar una evaluación que mide la eficacia general de la unidad y su capacidad actual para continuar con su misión.
La red neuronal de Evaluación de Combate determina el nivel de combate actualmente en curso, si lo hay. Mide el nivel de combate como: Sin compromiso, Compromiso ligero, Compromiso medio o Compromiso fuerte. Las redes de Evaluación de Amenazas y Evaluación de la Misión también consideran el resultado de esta red como parte de su entrada de decisión.
La red neuronal Threat Evaluation evalúa el estado implícito de la amenaza. Esta red considera información como la posición relativa del enemigo y la actividad del enemigo y llega a una evaluación general de la amenaza. El nivel de amenaza introduce la probabilidad de un enfrentamiento si la unidad continúa con su misión actual.

Figura 5. EAGLE evalúa la estructura de decisión de la actividad operativa
La red neuronal de Evaluación de la Misión evalúa el estado actual de la misión de la unidad implícito en condiciones tales como el grado en que la unidad está actualmente comprometida con el enemigo, el estado de la misión en relación con su objetivo y la actividad actual de la unidad. Esta red decide cuál es el estado general de la misión. La segunda capa de la red produce el resultado principal de la estructura de decisiones: la decisión sobre qué perseguir como actividad operativa. Esta red neuronal recibe entradas de las redes neuronales de primera capa de Evaluación de combate, Evaluación de amenazas, Evaluación de misión y Autoevaluación y las variables adicionales Actividad operativa (que proporciona retroalimentación de decisiones anteriores), Estado de movimiento, Autointención y Tarea. Se asume que Task proporciona el orden Operation o Frag actual del comando de nivel superior. La salida de esta red es una actividad operativa, que determina qué actividad seguirá la unidad a continuación.
Otra función requerida por el modelo EAGLE es decidir cuándo hacer la transición a un nuevo objetivo. Una red neuronal Evaluar el siguiente objetivo determina si una unidad necesita hacer la transición de su actividad asignada a otra actividad (consulte la Fig. 6). Las razones de la transición incluyen la necesidad de una mejor defensa personal y mejores métodos para lograr el objetivo. Las condiciones de entrada incluyen la actividad operativa actual, el nivel de amenaza, la eficacia de la unidad, la intensidad del combate y las evaluaciones del estado de la misión realizadas por la estructura de decisión de evaluación de la actividad operativa. Esta red determina si la unidad debe hacer la transición a un nuevo objetivo y devuelve el nombre de la función que determinará el objetivo específico. Los posibles resultados incluyen: Continuar con el objetivo actual (es decir, sin cambios), Obtener el próximo objetivo planificado, Obtener el objetivo final, Obtener una posición de batalla apresurada, Atacar al enemigo de mayor amenaza, Obtener el objetivo de ruptura de contacto y Obtener el objetivo, la reserva amistosa más cercana Unidad móvil terrestre.

Figura 6. EAGLE evalúa el próximo objetivo estructura de decisión
Definición y entrenamiento de redes neuronales LINIAC
Antes de que una red neuronal pueda funcionar correctamente, debe ser entrenada. El entrenamiento establece los valores de conexión "neuronales" (pesos) entre los elementos vectoriales de entrada y salida de la red. Un LINIAC ANN conserva su formación al guardar información esencial en un archivo de texto externo. Este archivo es útil tanto para inicializar una instancia de una red neuronal en una aplicación cliente como para volver a ingresar al programa de entrenamiento para revisión o entrenamiento adicional. La inicialización del cliente se produce al cargar la información de la matriz de conexión del archivo en un almacén de datos que la ANN mantiene en la aplicación del cliente. Además de la matriz de conexión, este archivo contiene información para permitir que el motor de la red neuronal asigne valores de estado de entrada y salida a las ubicaciones correctas en los vectores de entrada y salida. También contiene los ejemplos utilizados para la formación, que pueden ser útiles para una revisión o reentrenamiento posterior.
Pathfinder Systems ha desarrollado el programa Course of Action Planner (COAP) como un programa interactivo basado en gráficos para proporcionar la capacidad de definir y entrenar redes neuronales fácilmente. Una vista proporciona la capacidad de definición de red, mientras que una segunda vista proporciona la capacidad de entrenamiento. Aparecen varios cuadros de diálogo en cada pantalla para proporcionar opciones para un escenario de entrenamiento completo. COAP realiza dos funciones principales; permite al usuario definir el conjunto de Condiciones y Estados que componen la red y capacita al usuario para entrenar o evaluar la red neuronal. La capacitación consiste en proporcionar un conjunto de ejemplos y ordenar a COAP que aprenda el comportamiento especificado en esos ejemplos.
Definición de una red neuronal
La ventana Definición de COAP proporciona dos cuadros de diálogo básicos (consulte la Fig. 7). El cuadro de la izquierda permite al usuario definir el conjunto de condiciones que considerará la red neuronal y el cuadro de la derecha permite al usuario especificar los estados que puede asumir cada condición. Las condiciones y los estados utilizan nombres simbólicos, que se utilizan de forma coherente a lo largo del proceso de definición y entrenamiento y para la ejecución real de la red neuronal en su aplicación.
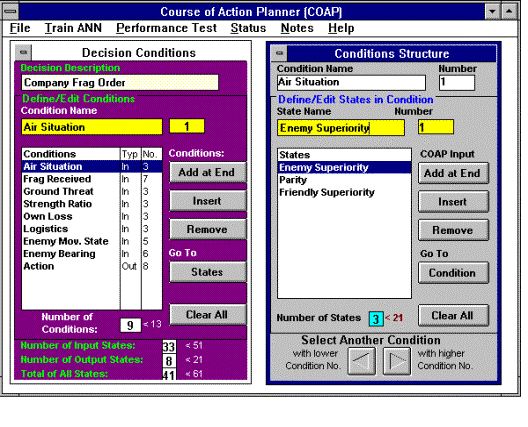
Figura 7. Interfaz de definición de red neuronal COAP
Estos nombres simbólicos definen las condiciones y sus estados utilizando terminología que es natural para el usuario. El trabajo del programador de aplicaciones es adaptar la interfaz de la red neuronal a la terminología que el diseñador de la red ha proporcionado; sin embargo, el archivo de entrada LINIAC incluye todos los nombres simbólicos usados por la red neuronal, lo que simplifica considerablemente esta tarea. Por supuesto, se debe tener cuidado para garantizar que la red neuronal use información que la aplicación pueda proporcionar convenientemente y que los estados de resultado también sean significativos para ella. El usuario tiene la libertad de agregar y modificar Condiciones y Estados hasta que esté satisfecho de que el conjunto representa adecuadamente las variables de decisión requeridas. Una vez que ha comenzado el entrenamiento, es posible cambiar los nombres simbólicos; sin embargo, agregar o eliminar condiciones o estados anula todo el entrenamiento previo y requiere que el entrenamiento se reinicie desde el principio. Una vez definido, COAP mantiene el conjunto de nombres de estado y condición, ejemplos de entrenamiento y valores de conexión (el entrenamiento) en el archivo de texto. Este archivo debe importarse a la aplicación de usuario para inicializar la matriz de conexión.
Entrenamiento de redes neuronales
La ventana Capacitación de COAP proporciona los modos de enseñanza y revisión (consulte la Fig. 8). El modo de enseñanza proporciona modos de operación en línea (Ejercicio directo) y en segundo plano (Tareas). El entrenamiento avanza definiendo un conjunto de valores de entrada y solicitando una decisión de la red haciendo clic en el botón "Mostrar resultados". El entrenador puede aceptar la decisión de que la red regrese, pero si la decisión no es deseable, el entrenador especifica la decisión correcta e instruye a la red neuronal para que “aprenda” el nuevo comportamiento. El usuario puede especificar que el aprendizaje ocurra en línea o puede ser puesto en la cola como "tarea" para el procesamiento por lotes más tarde. La capacitación en línea generalmente requiere de unos segundos a varios minutos por ejemplo para procesarse. El período de tiempo depende principalmente de la cantidad de ejemplos ya incorporados en la red y de qué tan cerca un nuevo ejemplo replica un ejemplo aprendido previamente. Dado que de treinta a cincuenta ejemplos pueden ser adecuados para proporcionar decisiones de salida aceptables en una amplia gama de condiciones de entrada, un usuario puede entrenar una red en un período de varias horas. En raras ocasiones, es posible que dos ejemplos de entrenamiento representen patrones que son inconsistentes, por lo que el algoritmo de entrenamiento no puede resolver las diferencias (es decir, el algoritmo de retropropagación no puede converger en una solución). Si esto sucede, es necesario revisar los ejemplos de entrenamiento, eliminar las anomalías y reentrenar la red.
El modo Revisión, que no se muestra en la Fig. 8, permite al entrenador revisar todo el entrenamiento previo. Dado que COAP conserva todos los ejemplos de entrenamiento en su archivo de texto externo, es posible dividir el entrenamiento en varias sesiones. Por tanto, el formador puede revisar la formación previa en una sesión posterior para su validación o para evitar entradas redundantes. Esto también permite al usuario volver a capacitarse o proporcionar capacitación adicional para una red neuronal si la capacitación inicial resulta ser incorrecta o inadecuada para la aplicación prevista.
COAP configura la Ventana de Entrenamiento y Evaluación para mostrar todas las Condiciones de entrada en la parte superior izquierda de la ventana. Debajo de cada nombre de condición, COAP muestra todos los estados que definen esa condición. Durante la sesión de entrenamiento, el usuario selecciona un estado para cada condición para un ejemplo de entrenamiento específico, luego selecciona la función Mostrar resultados. COAP responde mostrando el estado de salida correspondiente que tiene actualmente "memorizado". El capacitador puede responder de una de estas tres formas: aceptar el resultado si es consistente con los resultados deseados, rechazar el resultado o ignorarlo. Si el capacitador rechaza el resultado, COAP brinda la oportunidad de especificar la respuesta correcta y luego le pide al capacitador que inicie el aprendizaje. El aprendizaje ocurre ajustando los valores de la matriz de conexión para que la red produzca el resultado deseado para el estímulo dado sin violar el comportamiento aprendido previamente. Debido a que las redes neuronales pueden extrapolar patrones aprendidos previamente para que coincidan con patrones de entrada similares, no es necesario que el entrenador presente muchos patrones similares para entrenar la red de manera efectiva. Esta capacidad de extrapolación reduce considerablemente el tiempo de entrenamiento y convierte a la red neuronal en una herramienta muy rentable.

Figura 8. Interfaz de entrenamiento de red neuronal COAP
Otra función COAP disponible en el modo Revisión es la opción Prueba de rendimiento. Esta opción realiza una serie de ejecuciones secuenciales de la red neuronal y muestra el tiempo medio de ejecución al usuario. El tiempo promedio variará de unos pocos milisegundos a unas pocas decenas de milisegundos en una PC 80486 de 33 MHz, dependiendo de la complejidad de la red neuronal. Esto contrasta favorablemente con muchas otras implementaciones actuales de redes neuronales, que requieren tiempos de cálculo sustanciales. La velocidad del ciclo de cálculo de LINIAC lo hace bastante atractivo para muchas aplicaciones, ya que normalmente puede realizar de uno a varios órdenes de magnitud más rápido que las implementaciones algorítmicas o basadas en reglas comparables.
Conclusión
Este artículo ha presentado un enfoque práctico para el uso de redes neuronales artificiales para realizar la toma de decisiones automatizada en el contexto de simulaciones de combate. Las redes neuronales pueden ser mucho más fáciles de diseñar e implementar que los algoritmos o bases de reglas comparables. Un solo motor de red neuronal puede funcionar como servidor para un número arbitrario de redes neuronales. El "código" necesario para ejecutar una red neuronal se puede encapsular en un archivo de datos externo, que incluye tanto la matriz de conexión como las definiciones de condición / estado para los vectores de entrada y salida. Debido a esta codificación externa, el comportamiento de un cliente se puede modificar simplemente sustituyendo un ANN entrenado de manera diferente sin cambiar el código fuente. Esto reduce en gran medida la cantidad de tiempo y los gastos necesarios para diseñar, implementar y mantener la lógica / código de decisión para las fuerzas automatizadas. En las simulaciones, esto proporciona una flexibilidad esencial porque es posible que el comportamiento de las fuerzas automatizadas deba cambiar para reflejar diferentes escenarios. Esto también permite reemplazar las redes neuronales cuyo entrenamiento inicial puede contener deficiencias.
Debido a que es posible entrenar redes neuronales usando una interfaz gráfica relativamente simple, es posible hacer que los “expertos” los entrenen rápida y directamente sin requerir personal técnico intermedio que puede introducir inadvertidamente sesgos personales en la base de decisiones. Esta interfaz de usuario también proporciona la capacidad de revisar el entrenamiento y el comportamiento de una red neuronal y, por lo tanto, proporciona una validación de primer nivel para el comportamiento de la red. Las redes neuronales reflejan sus ejemplos de entrenamiento de manera muy fiel y evitan errores innecesarios causados por anomalías de codificación. También son muy buenos para reflejar el comportamiento extrapolando ejemplos aprendidos para cubrir condiciones para las que no tienen una formación específica, lo que reduce en gran medida el tiempo que los expertos deben dedicar a la formación. La implementación de la red neuronal LINIAC posee una velocidad de ejecución muy rápida, e incluso una estructura de múltiples redes neuronales que operan secuencialmente para producir una sola decisión puede superar fácilmente una implementación algorítmica o basada en reglas comparable. Finalmente, PSI ha verificado su desempeño, confiabilidad y precisión en varios proyectos de demostración.