PATHFINDER
SYSTEMS, INC.
Battlefield-simulatie
Geautomatiseerde Battlefield Simulation Command and Control met behulp van kunstmatige neurale netwerken
Stewart H. Jones, Ivan J. Jaszlics en Sheila L. Jaszlics
Pathfinder Systems, Inc.
Lakewood, Colorado 80228
Abstract
Hedendaagse gedistribueerde interactieve gevechtssimulaties worden steeds groter en complexer en daarom moeilijker te beheren. Het succes van toekomstige projecten zal gedeeltelijk afhangen van het vermogen om aspecten van het bevel en de controle over de strijdkrachten op een geautomatiseerde en zeer voorspelbare manier te beheren. Kunstmatige intelligentie in het algemeen en kunstmatige neurale netwerken in het bijzonder bieden aantrekkelijke mechanismen om commandovoering en controle te automatiseren. Pathfinder Systems heeft het Linear Interactive Activation and Competition (LINIAC) Model Artificial Neural Network ontwikkeld, een high-speed, objectgeoriënteerd model, voor gebruik in verschillende gevechtssimulaties en heeft aangetoond dat dit een haalbare toepassing van deze technologie is. LINIAC is zeer geschikt voor het leveren van geautomatiseerde besluitvormings- en gevechtsbeheerfuncties voor een verscheidenheid aan constructieve slagveldsimulaties. Het emuleert de besluitvormingsfuncties van tactische eenheidscommandanten en hun staven, zoals weergegeven door roleplayer / controllers in commandopostoefeningen. LINIAC gebruikt een objectgeoriënteerd ontwerp dat een situatiepatroon herkent en een overeenkomstige uitkomst geeft in een tijdsbestek van enkele of enkele tientallen milliseconden. Een belangrijk voordeel van LINIAC is dat de training is gecodeerd in en geïnitialiseerd vanuit een externe datastructuur in plaats van hard gecodeerd als rule-bases of algoritmen. Daarom is het mogelijk om LINIAC-netwerken eenvoudig te vervangen of opnieuw te trainen om aan nieuwe vereisten te voldoen zonder de code te wijzigen. LINIAC training maakt gebruik van een grafische interface, zodat trainers geen computertaaltraining of speciale computervaardigheden nodig hebben. Experts met gespecialiseerde kennis kunnen hun kennis direct in neurale netwerken opnemen zonder de hulp van een Knowledge Engineer. Een trainer kan doorgaans twee of drie dozijn trainingsvoorbeelden per uur invoeren. Pathfinder Systems heeft het vermogen aangetoond om kunstmatige neurale netwerken van LINIAC te gebruiken in verschillende gevechtssimulatieprogramma's om geautomatiseerde commandovoering en controle te bieden over ten minste een deel van de troepen in de simulatie. De resultaten van deze projecten hebben aangetoond dat het gebruik van neurale netwerken van LINIAC het menselijke besluitvormingselement in gevechtssimulaties met succes kan emuleren met resultaten die gelijkwaardig zijn aan wat menselijke rollenspelers en geautomatiseerde regelbases kunnen bieden.
Invoering
Een fundamentele overweging bij het ontwerpen van slagveldsimulaties is dat ze het realisme zo getrouw mogelijk benaderen. Een moeilijkheid bij het simuleren van commando en controle op het slagveld is het repliceren van het besluitvormingsproces waarop het is gebaseerd. Het doel van veel simulaties is om een deel van het publiek te trainen om acceptabele gevechtsbeslissingen te nemen. Hier is het passend om menselijke operators besluitvormingsfuncties te laten uitvoeren. Het gebruik van menselijke rollenspelers om beslissingen te nemen voor de tegengestelde troepen, of vriendelijke aangrenzende en achterste troepen kan echter contraproductief zijn en geautomatiseerde commandovoering en controle kan zeer wenselijk zijn. Om dergelijke automatisering te bieden, zijn veel huidige simulaties sterk afhankelijk van beslissingsalgoritmen en regelbases in combinatie met menselijke rollenspelers om het menselijke element te bieden. Er kunnen zich problemen voordoen omdat algoritmen en regelbases mogelijk niet voldoende foutloos zijn en menselijke resources voor rollenspelers soms moeilijk te beheersen zijn. Automatisering met behulp van algoritmen en regelbases kan ook onvoldoende flexibiliteit hebben om te voldoen aan veranderende scenariovereisten zonder uitgebreide programmering. Kunstmatige neurale netwerken (ANN's) bieden een kosteneffectief alternatief voor algoritmen en regelbases voor het genereren of repliceren van menselijke besluitvorming. ANN's zijn effectief omdat ze gebaseerd zijn op voorbeelden, in plaats van hardgecodeerde implementaties.
Dit artikel beschrijft een benadering die Pathfinder Systems, Inc. (PSI) heeft gevolgd om ANN's toe te passen om Command and Control voor militaire simulaties te automatiseren. PSI heeft het LINIAC Neural Network-model ontwikkeld voor het emuleren van Command and Control-beslissingen. Het is gebruikt voor demonstraties met de Brigade/Battalion Battle Simulation (BBS), binnen het BBS-SIMNET Interoperation-project om beslissingen te genereren voor SIMNET Semi-Automated Forces, en in ROLEPLAYER, een zeer eenvoudige slagveldsimulatie, die een praktisch gebruik van LINIAC neurale netten op peloton-, compagnie- en bataljonsniveau. Een ander voorbeeld, dat momenteel wordt ontwikkeld door PSI en de MITER Corporation, is de toepassing van ANN's op het EAGLE-gevechtssimulatiemodel. Momenteel is de EAGLE-simulatie sterk afhankelijk van op regels gebaseerde beslissingen. Dit project is bedoeld om de haalbaarheid aan te tonen van het vervangen van regelbases op het laagste niveau van commando en controle in een complexe simulatie met ANN's.
De behoefte aan flexibele AI-commando's en -controle
Er zijn enkele duidelijke problemen met het gebruik van algoritmen en regelbases om menselijke besluitvorming te repliceren. Meestal zijn ze hard gecodeerd en zijn ze moeilijk te veranderen als de behoeften van de simulatie veranderen. Recente wereldwijde militaire ontwikkelingen, zoals de ontbinding van de Sovjet- en Oostblok-troepen en de opkomst van strijdkrachten uit de derde wereld, hebben de commando- en controlevereisten voor gevechtssimulaties veranderd. Tegenwoordig moeten ze flexibel genoeg zijn om een verscheidenheid aan militaire doctrines en operatiemethoden te accommoderen, waarbij vaak een snelle herconfiguratie nodig is. Als het nodig is om algoritmen en regelbases te implementeren met behulp van syntactisch rigide programmeertalen of talen voor gegevensinvoer, vereist hun ontwikkeling programmeertechnici om de commando- en controlevereisten te vertalen in de juiste taalsyntaxis. De stappen die nodig zijn om de kennis van experts te vertalen in een geformaliseerde syntaxis, introduceren de mogelijkheid van miscommunicatie en misverstanden, wat kan leiden tot programmafouten. Zelfs als er een goed begrip bestaat, kunnen logische fouten onbedoeld worden gegenereerd. Er is een aanzienlijke hoeveelheid testen vereist om dergelijke fouten te detecteren en te verwijderen. Ten slotte moeten regelbases en algoritmen gewoonlijk rekening houden met alle mogelijke onvoorziene omstandigheden bij het analyseren van een probleem, zodat niet-verklaarde omstandigheden geen onbedoelde resultaten in de simulatie zullen genereren. Er zijn aanzienlijke technische inspanningen nodig om ervoor te zorgen dat alle redelijke situaties in de code worden weergegeven.
Het gebruik van kunstmatige neurale netten voor geautomatiseerde commandovoering en controle kan veel van deze beperkingen overwinnen. ANN's kunnen worden geïmplementeerd als een objectklasse met standaardinterface- en beslissingsmethoden. Een simulatie kan dan veel beslissingsobjecten van die klasse creëren, elk met zijn unieke omgeving bestaande uit invoerinformatie en een "verbindingsmatrix" die het gedrag van een bepaalde ANN inkapselt. De beslissingsmethode is een relatief eenvoudig wiskundig proces dat geldig is voor een breed scala aan beslissingstoepassingen. Een goed ontworpen ANN-object is geschikt voor elke compatibele beslissingsbasis en repliceert getrouw de cognitieve redenering waarmee het is getraind.
Het is mogelijk om trainingsmethoden voor ANN's te ontwerpen met behulp van standaard grafische interfacetechnieken die geen programmeerkennis van de trainer vereisen, zodat kennisexperts ze direct kunnen trainen zonder afhankelijk te zijn van een technische tolk. Experts kunnen snel, vaak intuïtief, leren hoe ze dergelijke interfaces kunnen gebruiken om ANN's rechtstreeks te trainen in sessies die slechts een uur of twee duren. Experts kunnen ook de commando- en controlevariabelen definiëren met behulp van Engelse woorden en zinsdelen die zowel voor de trainer als voor het trainingspubliek logisch zijn. Bij het trainen van ANN's is het niet nodig om voorbeelden te geven voor alle mogelijke invoercombinaties, zoals in het algemeen het geval is met algoritmen en regelbases. Een neuraal net kan duizenden tot honderdduizenden mogelijke invoercombinaties hebben, maar een kleine, representatieve steekproef van het totaal is voldoende voor een adequate training. ANN's zijn erg goed in het extrapoleren van de voorbeelden waarmee ze zijn getraind om andere, vergelijkbare voorbeelden te behandelen. De sleutel tot een goede training is natuurlijk om voorbeelden op te nemen die een zo breed mogelijk scala aan invoervoorwaarden dekken.
Als een simulatie meerdere scenario's moet kunnen accommoderen om verschillende militaire doctrines of werkingsmodi weer te geven, dan is het mogelijk om ANN's voor elk scenario te trainen en geschikte ANN-objecten voor het gespecificeerde scenario te initialiseren met het vereiste gedrag bij het starten van de simulatie in plaats van te wijzigen de simulatiecode. Deze techniek is ook van toepassing op geautomatiseerde command and control voor meerdere echelons. De beslissingsstructuur voor verschillende echelons kan vergelijkbaar zijn in die zin dat elk echelon naar dezelfde reeks voorwaarden kijkt en gelijkwaardige beslissingen neemt. Het enige verschil kan zijn dat elk echelon verschillende redeneringen kan gebruiken om tot vergelijkbare beslissingen te komen. Daarom is het mogelijk om een enkele beslissingsstructuur op meerdere echelons toe te passen, maar laat elk echelon een set ANN-objecten gebruiken die uniek zijn getraind om zijn individuele redenering weer te geven.
Ten slotte is het mogelijk om neurale netwerken stapsgewijs te trainen. Als een ANN ongepast gedrag vertoont binnen een simulatie, is het mogelijk om deze snel om te scholen. In feite is trainen door middel van simulatiescenario's een zeer effectieve trainingsmethode.
Het model voor lineaire interactieve activering en competitie (LINIAC)
Als onderdeel van zijn onderzoek naar het gebruik van ANN's voor commando- en controletoepassingen, heeft Pathfinder Systems, Inc. het ANN-model voor lineaire interactieve activering en competitie (LINIAC) ontwikkeld. Figuur 1 illustreert hoe het LINIAC-model beslissingen neemt. Elke LINIAC ANN bestaat uit een invoervector, weergegeven als naar beneden wijzende pijlen, een uitvoervector, weergegeven als naar rechts wijzende pijlen, en een verbindingsmatrix. De invoervector definieert een reeks invoervoorwaarden, waarbij elke voorwaarde een van twee of meer toestanden kan aannemen. Het werkelijke aantal voorwaarden en toestanden voor een bepaalde ANN is willekeurig, maar kan niet veranderen nadat de ANN is getraind zonder dat herscholing nodig is. In het LINIAC-model kan elke voorwaarde slechts één toestand aannemen, die wordt uitgedrukt door een 1-waarde, terwijl alle andere toestanden voor die voorwaarde worden uitgedrukt door een 0-waarde (hoewel gewogen numerieke waarden ook mogelijk zijn). De LINIAC-uitgangsvector bestaat uit één voorwaarde ook met een willekeurig aantal toestanden. De zwarte stippen, weergegeven op het snijpunt van elke horizontale en verticale pijl, vertegenwoordigen de neurale verbindingen tussen invoer- en uitvoervectorelementen en de grootte van elke stip suggereert de relatieve sterkte of "gewicht" van de verbinding. Het gewicht bepaalt hoe sterk elke ingangstoestand de corresponderende toestand van de uitgangsvector beïnvloedt. Een LINIAC-beslissing wordt altijd geselecteerd als de uitvoerstatus met de grootste cumulatieve waarde. De sleutel tot de succesvolle werking van LINIAC is het vaststellen van de waarden van de verbindingsmatrix tijdens de training, zodat een bepaald invoerpatroon altijd het resultaat oplevert dat de trainer heeft gespecificeerd.

Fig 1. LINIAC artificieel neuraal netconcept
Neural Net-toepassing voor geautomatiseerde commando's en besturing
Er zijn veel manieren om neurale netwerken toe te passen op geautomatiseerde commandovoering en controle, variërend van enkelvoudige neurale netwerken tot zeer complexe beslissingsstructuren die zijn samengesteld uit lagen van neurale netwerken. De resterende discussie zal zich concentreren op de verschillende voorbeelden/modellen ontwikkeld door of in ontwikkeling door PSI. Een voordeel van de Neural Net-benadering is de mogelijkheid om relatief eenvoudige beslissingen te groeperen in een complexe beslissingsstructuur. Dit is analoog aan de manier waarop complexe organisatorische beslissingen doorgaans worden genomen. Een ander voordeel is dat deze benadering de ontwerper in staat stelt om complexe beslissingen op te delen in eenvoudige componenten die veel gemakkelijker te ontwerpen, te begrijpen en te trainen zijn.
Het succes of falen van het gebruik van ANN's zal sterk afhangen van de validiteit van het ontwerp van het beslissingsmodel. Het onderstaande model is een van de vele mogelijke concepten. De waarde van deze benadering is dat eenvoudige elementen kunnen worden ontworpen, opnieuw ontworpen en opnieuw kunnen worden verbonden tot een structuur die het besluitvormingsproces van een echte militaire eenheid nauwkeurig weergeeft. Een werkbare beslissingsstructuur zal waarschijnlijk een hybride zijn van algoritmen, regels en neurale netwerken die samenwerken. Er zijn algoritmen nodig om simulatiegegevens om te zetten in gegevenstypen (dwz beslissingsvariabelen) die geschikt zijn voor invoer in de ANN's van de beslissingsstructuur. Niet alle soorten beslissingen kunnen het beste worden geïmplementeerd via neurale netwerken - wanneer het aantal invoermogelijkheden en het aantal uitkomsten klein is, zijn algoritmische regels meestal een betere keuze. We hebben de neiging om neurale netten te gebruiken wanneer de mogelijke combinaties van de inputs, zelfs als ze niet vaag zijn, in de duizenden of honderdduizenden kunnen lopen.
Het trainen van een net is bijna triviaal als het wordt uitgevoerd door een materiedeskundige. Wat erg belangrijk is, is om de algemene beslissingsstructuur te bepalen voor een activiteit die wordt weergegeven door een ANN (dit kan bijvoorbeeld een specifieke menselijke C2 zijn functie, zoals "pantser BN S2 - de huidige situatie evalueren"). Het is te verwachten dat een ontwerp van een beslissingsstructuur een evolutionair proces zal ondergaan dat het realisme ervan zal verbeteren. De belangrijkste elementen van een ontwerp omvatten de reeks beslissingen (de ANN's) die de simulatie vereist op elk commando- en controlepunt, de structuur van elk beslissingsproces (de voorwaarden en toestanden van elke ANN), de verbindingen met de simulatiedatabase en de onderlinge verbindingen tussen de geselecteerde ANN's. Hoe individuele ANN's worden getraind, is in eerste instantie van minder belang, omdat training of herscholing na implementatie kan plaatsvinden.
Het Rollenspelermodel
PSI ontwikkelde oorspronkelijk het ROLEPLAYER-model om de haalbaarheid aan te tonen van het gebruik van ANN's in plaats van menselijke rollenspelers om delen van een gevechtssimulatie te besturen. ROLEPLAYER demonstreert de interactie tussen verschillende vriendelijke (blauwe) bataljons, bestuurd door een menselijke operator, en verschillende tegengestelde (rode) bataljons die voornamelijk worden bestuurd door ANN's. Het model gebruikt zes neurale netten: drie op bataljonsniveau (zie figuur 2); twee op bedrijfsniveau (zie Fig. 3); en één op pelotonniveau (zie Fig. 4). Elk net ontvangt een aantal invoervoorwaarden, die boven elk beslissingsvak worden vermeld, en produceert een enkele uitkomstbeslissingswaarde. Elke invoervoorwaarde en de uitvoerbeslissing worden beschreven als een reeks toestanden (niet getoond in deze figuren). Elke voorwaarde kan één of geen toestand in de set aannemen. De gespecificeerde toestand definieert de neurale activeringswaarde voor zijn toestand. De conditie Enemy Move State, die een invoer is voor alle drie de neurale netwerken, kan bijvoorbeeld een van de staten aannemen: marcheren, aanvallen, stoppen, verdedigen en terugtrekken. Het ROLEPLAYER-model biedt statuswaarden voor deze voorwaarden via conventioneel gecodeerde regels en algoritmen.
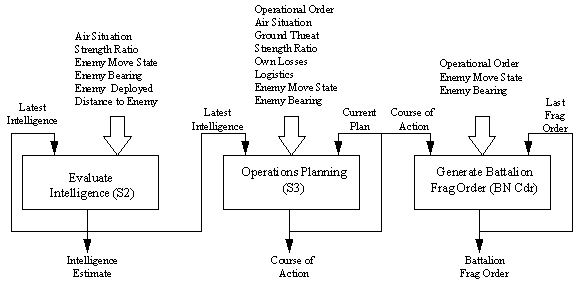
Fig 2. Beslissingsstructuur van rollenspelerbataljon
Het neurale netwerk Evaluate Intelligence biedt een algemene schatting van de intelligentie van de vijand op basis van observaties die zijn gecodeerd in de invoervoorwaarden. Dit netwerk wordt periodiek, eens in de vijf minuten, uitgevoerd om een actuele beoordeling te maken. Het kan ook reageren op gebeurtenissen die wijzen op plotselinge veranderingen in de tactische situatie. Het net bootst de tactische situatie-evaluatie-activiteit van de inlichtingenofficier van het bataljon (S2) na. De juiste materiedeskundige om dit net te trainen zou een echt bataljon S2 zijn. Tabel 1 toont de voorwaarden en toestanden van dit neurale net. De eerste kolom definieert de voorwaarden (invoer "pools") en alle kolommen aan de rechterkant beschrijven de mogelijke toestanden die elke voorwaarde kan aannemen. De bovenste rijen zijn de set invoervoorwaarden en de onderste rij is de uitvoerbeslissing. Verschillende voorwaarden, zoals luchtsituatie en sterkteverhouding, hebben willekeurige maatstaven, hoewel in termen die een menselijke beslisser waarschijnlijk zal overwegen. Het ROLEPLAYER-model is in staat om werkelijke statistieken naar deze categorieën te vertalen, maar om de begrijpelijkheid van de gebruiker te verbeteren, is het waarschijnlijk beter om de Strength Ratio te definiëren met behulp van toestanden zoals "Minder dan 1:2" (Laag) en "Groter dan 2:1" (Hoog). ). Houd er rekening mee dat de intelligentieschatting, "Intel Estimate", ook een feedbackpad heeft naar het neurale netwerk Evaluate Intelligence en een invoer is in het neurale netwerk voor operationele planning. De input in het operationele planningsnet vertegenwoordigt de communicatie van de S2 naar de Operations Officer (S3). De feedback van eerdere aanbevelingen in het net zelf geeft aan dat de situatie-evaluatie waarschijnlijk niet onmiddellijk zal veranderen, zonder rekening te houden met eerdere schattingen. Omstandigheden die vanuit het ene neuraal net worden uitgevoerd en in een ander net worden ingevoerd, moeten identieke sets van mogelijke toestanden hebben.
Het bataljon Operations Planning neurale netwerk ontvangt de Operational Order en Fragmentary Operational Orders (Frag Orders) van het hogere hoofdkwartier (zie tabel 2). Het beschouwt deze volgorde samen met andere voorwaarden, waaronder de Intelligence Estimate-uitvoer van het Evaluate Intelligence neurale net en bepaalt welke actie moet worden ondernomen op bataljonsniveau. Dit netwerk voert periodiek, eens per vijf minuten of als reactie op kritieke tactische toestandsveranderingen, uit om een actuele koers te bepalen. Afhankelijk van de invoercondities en de gecodeerde training zal de ANN aanbevelen om de huidige missie voort te zetten, of een andere, meer passende, handelwijze te volgen. Het emuleert in wezen de onmiddellijke herplanning van operaties en het bepalen van de actiekoers van de Bataljon Operations Officer (S3). De optimale materiedeskundige om dit net te trainen is een echte S3 voor Blue Forces, of een inlichtingenofficier die bekend is met vijandelijke doctrine, uitrusting en tactieken voor de Opposing Force (OPFOR). Dit net beschouwt ook zijn laatste aanbeveling als een van de inputs en geeft zijn aanbeveling aan het bataljon Fragmentary Operational Order (Frag Order) net.
Voorwaarde
Laatste schatting
Luchtsituatie:
Sterkteverhouding:
Staat van vijandelijke verplaatsing
vijandelijke peiling
vijand ingezet
Afstand tot vijand
Intelligentie schatting
Staten
Geen bedreiging
vijandelijke overste
Hoog
maart
Vooruit
Ja
In de buurt
Geen bedreiging
Verre dreiging
Pariteit
Gelijkwaardig
Aanval
Flank
Nee
Ver
Verre dreiging
Vijand in de verdediging
Vriendelijke Superior
Laag
Halt
Achter
Geen
Vijand in de verdediging
dreigende aanval
Verdedigen
dreigende aanval
omsingeld
Intrekken
omsingeld
Achterste dreiging
Achterste dreiging
Flankdreiging
Flankdreiging
Tabel 1. Rollenspeler evalueert neurale netwerkstructuur van intelligentie
Flankdreiging
Verdedigen
Missie verlaten
omgeving deed
Uitschakelen
Missie verlaten
Grijp doel
Positie verdedigen
dreigende aanval
Tactische zet
Omringen
Positie verdedigen
Verkennen
Vriendelijke Superior
Aanval
Vijand in de verdediging
Geen
Laag
Hoog
rood
Halt
Achter
Aanval
Verdedigen
Pariteit
Bedreiging verminderen
Verre dreiging
Ver
Gelijkwaardig
Medium
Amber
Aanval
Flank
Bedreiging verminderen
Staten
Weg maart
vijandelijke overste
Doorgaan met missie
Geen bedreiging
In de buurt
Hoog
Laag
Groente
maart
Vooruit
Doorgaan met missie
Voorwaarde
Operatievolgorde:
Luchtsituatie:
Huidige plan
Laatste intelligentie
grondbedreiging
Sterkteverhouding:
eigen verliezen
Logistiek
Staat van vijandelijke verplaatsing
vijandelijke peiling
Werkwijze
Achterste dreiging
Tabel 2. Neurale netstructuur van rollenspelerbataljons
Het neuraal netwerk Frag Order van het bataljon is verantwoordelijk voor het beslissen welke Frag Orders het bataljon naar de compagniescommandanten onder zijn bevel zal sturen. Tabel 3 toont de invoervoorwaarden die dit net in overweging neemt en de uitvoerbeslissing in de laatste rij. Het wordt periodiek uitgevoerd, eens in de vijf minuten, of als reactie op tactische noodsituaties, om een nieuwe Frag Order te produceren. Het beschouwt het besluit over de te volgen koers, opgesteld door de Bataljonsoperaties ANN, en ook het eerder uitgevaardigde Frag-bevel als feedback op de eerdere uitvoering ervan. De meest voorkomende uitkomst van deze ANN is een "Doorgaan"-beslissing, wat betekent dat er geen verandering is in de volgorde die elk bedrijf moet uitvoeren. Nogmaals, de beslissing die het daadwerkelijk neemt, hangt af van hoe het netwerk is getraind. Je zult misschien opmerken dat de invoervoorwaarden voor elk van deze neurale netwerken willekeurig lijken. Wat wordt opgenomen als invoervoorwaarden voor een neuraal net, is een beslissing die de simulatieontwerper samen met militaire vakexperts moet nemen.
Uitschakelen
Uitschakelen
Voorwaarde
Operatievolgorde:
Laatste Frag uitgegeven
Werkwijze
Staat van vijandelijke verplaatsing
vijandelijke peiling
Tragvolgorde
Staten
Weg maart
Doorgaan met
Doorgaan met missie
maart
Vooruit
Doorgaan met
Verdedigen
Halt
Bedreiging verminderen
Aanval
Flank
Halt
Verkennen
maart
Aanval
Halt
Achter
Aanval
Grijp doel
Aanval
Positie verdedigen
Tactische zet
omsingeld
Aanval
Positie verdedigen
Missie verlaten
Uitschakelen
Positie verdedigen
Terugtrekken vechten
Verdedigen
Terugtrekken vechten
Tabel 3. Rollenspeler-taskforce frag-volgorde neurale netstructuur
De commando- en controlefuncties van de ROLEPLAYER Company omvatten twee neurale netwerken: de ene geeft Frag Orders aan de pelotons onder het commando van de compagnie en de andere geeft verzoeken om vuursteun uit wanneer dat nodig is (zie figuur 3). Het neuraal netwerk Company Frag Order is verantwoordelijk voor het beslissen welke Frag Orders de compagniescommandant aan zijn pelotons zal geven. Het emuleert de functie van de compagniescommandant in de onmiddellijke tactische controle van de ondergeschikte pelotons (zie tabel 4). Het wordt ongeveer eens per twee minuten uitgevoerd, of als reactie op tactische noodsituaties, om een nieuwe Frag Order te produceren. Het neemt de Frag Order van het bataljon in aanmerking die is uitgevaardigd door de commandant van de Task Force en zal over het algemeen een overeenkomstige Frag Order aan de pelotons uitvaardigen, tenzij de training het anders opdraagt, afhankelijk van de huidige invoeromstandigheden. De Roleplayer-simulatie evalueert omstandigheden, zoals Strength Ratio, in verhouding tot de sterkte van het vijandige bedrijf van de tegenstander zoals deze momenteel wordt waargenomen in de simulatie. Een "Doorgaan"-resultaat leidt ertoe dat het peloton zijn huidige activiteit voortzet. Als het bedrijf een nieuwe Frag Order heeft uitgevaardigd, zal het neurale netwerk van het peloton doorgaans besluiten om die order op te volgen, tenzij andere voorwaarden een andere beslissing vereisen.
Het neurale netwerk van het Fire Support Request evalueert de behoefte aan externe ondersteuning (zie tabel 5). De steun die binnen de mogelijkheden van ROLEPLAYER kan worden ontvangen, is indirect vuur of luchtsteun. Het emuleert de functies van een Company Fire Support Team. Het besluit, "Actie", zal zijn dat er momenteel geen vuursteun nodig is, of dat dit het geval is. Als er om ondersteuning wordt gevraagd, zorgt dit ervoor dat ROLEPLAYER het vuursteunverzoek doorgeeft aan een extra kunstmatig neuraal net (niet getoond), het Bataljons Vuursteun Coördinatienet (FSC-net). Het FSC-net zal, afhankelijk van de beschikbare middelen en van de bataljonsniveau-evaluatie van de tactische situatie, het verzoek inwilligen of afkeuren. Als het verzoek wordt ingewilligd, beslist het FSC-net ook over de toewijzing van geschikte middelen (indirecte vuur- of luchtsteun) en zet het de uitvoering van de ondersteunende activiteit in gang. Tijdvertragingen tussen goedkeuring van ondersteuningsverzoeken en daadwerkelijke ondersteuning zijn te wijten aan factoren die direct deel kunnen uitmaken van de simulatie (zoals de beweging van vliegtuigen), en factoren die indirect in de simulatie zijn opgenomen (extra C3-vertragingen, tijd die nodig is om branden te verschuiven, starttijd van gereed vliegtuig, enz.).
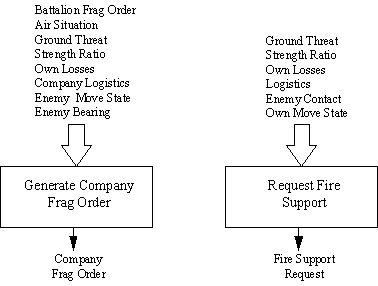
Figuur 3. ROLEPLAYER bedrijfsbeslissingsstructuur
Het neuraal netwerk Platoon Frag Order (zie figuur 4) is verantwoordelijk voor het beslissen welke Frag Orders de pelotonsleider zal uitvaardigen. Het emuleert de directe tactische controlefunctie van de pelotonsleider. Het wordt ongeveer één keer per minuut uitgevoerd om een nieuwe Frag Order te produceren. Tabel 6 toont de invoervoorwaarden voor dit neurale net. De onderste rij toont de outputbeslissing. Een "Doorgaan"-resultaat leidt ertoe dat het peloton zijn huidige activiteit voortzet. Als het bedrijf een nieuwe Frag Order heeft uitgevaardigd, zal het neurale netwerk van het peloton doorgaans besluiten om die order op te volgen, tenzij andere voorwaarden een andere beslissing vereisen. Wanneer het peloton het bevel geeft, zullen alle eenheden in het peloton dat bevel opvolgen, tenzij ze worden geïmmobiliseerd of vernietigd.
Uitschakelen
Uitschakelen
Voorwaarde
Frag-bestelling ontvangen
Luchtsituatie:
grondbedreiging
Sterkteverhouding:
eigen verliezen
Logistiek
Staat van vijandelijke verplaatsing
vijandelijke peiling
Actie
Staten
Doorgaan met
vijandelijke overste
In de buurt
Hoog
Laag
Groente
maart
Vooruit
Doorgaan met
Halt
Pariteit
Ver
Gelijkwaardig
Medium
Amber
Aanval
Links vooruit
Halt
maart
Vriendelijke Superior
Geen
Laag
Hoog
rood
Halt
Rechtdoor
maart
Aanval
Verdedigen
Linkerflank
Aanval
Positie verdedigen
Intrekken
Rechterflank
Positie verdedigen
Terugtrekken vechten
Achter
Terugtrekken vechten
Meerdere fragmenten
Tabel 4. Neurale netstructuur van rollenspelerbedrijf frag-orde
Geen
Laag
Hoog
rood
Ander
Meer dan 800 meter
Gelijkwaardig
Medium
Amber
Nee
Verdedigen
Bel ondersteuning
Staten
Binnen 800 meter
Hoog
Laag
Groente
Ja
Aanval
Geen ondersteuning nodig
Voorwaarde
grondbedreiging
Sterkteverhouding:
eigen verliezen
Logistiek
In contact
Eigen bewegingsstatus
Actie
Tabel 5. Neural net verzoek om ondersteuning bij brand van roleplayer-bedrijf
Neurale nettoepassing op EAGLE-beslissingsmodel
Momenteel is PSI bezig met het aanpassen van neurale netwerken om enkele beslissingen op laag niveau te nemen in de EAGLE-gevechtssimulatie. EAGLE is een gevechtsmodel op korps-/divisieniveau met resolutie voor het manoeuvrebataljon, bedoeld voor gebruik als analysehulpmiddel voor gevechtsontwikkeling. Er zijn ten minste twee kandidaat-gebieden voor het nemen van beslissingen over neurale netwerken geïdentificeerd. De ene plant de huidige operationele activiteit en de andere bepaalt wanneer naar de volgende doelstelling moet worden overgegaan.
Planning en Ordering vereist het beoordelen van de huidige situatie en mogelijke opties voor een nieuw plan, en vervolgens het uitgeven van nieuwe orders om het nieuwe plan uit te voeren. Op divisie-/korpsniveau vereist planning/herplanning het bepalen van een opeenvolging van gefaseerde operaties, en binnen elke fase, het selecteren van meerdere doelstellingen en taken voor de verschillende eenheden op lagere niveaus. Op bataljonsniveau (het laagste niveau in EAGLE) voert elke eenheid alleen de opdrachten uit die aan haar zijn doorgegeven. Bataljons zouden echter de speelruimte moeten hebben om opnieuw plannen te maken in die mate dat ze van die bevelen kunnen afwijken, indien nodig, voor zelfverdediging of wanneer een andere manier van handelen effectiever zou zijn om hun doel te bereiken. Op divisie- en brigadeniveau bestaat herplanning uit het uitwerken van divisieorders in die mate dat ze brede orders opsplitsen in meer gedetailleerde taken en doelstellingen die kunnen worden toegewezen aan eenheden op een lager niveau.
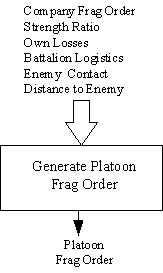
Figuur 4. Beslissingsstructuur ROLEPLAYER peloton
Meerdere Frag
Terugtrekken vechten
Terugtrekken vechten
Positie verdedigen
Positie verdedigen
Aanval
Aanval
maart
Laag
Hoog
rood
maart
Halt
Gelijkwaardig
Medium
Amber
Nee
Nee
Halt
Staten
Doorgaan met
Hoog
Laag
Groente
Ja
Ja
Doorgaan met
Voorwaarde
Frag-bestelling ontvangen
Sterkteverhouding:
eigen verliezen
Logistiek
In contact
Vijand binnen 1000 meter
Actiebesluit
Uitschakelen
Uitschakelen
Tabel 6. Neurale netstructuur van rollenspelpeloton frag-orde
De EAGLE-simulatie gebruikt meer beslissingsvariabelen op bataljonsniveau dan een enkel neuraal net zou moeten verwerken binnen ons sterk antropomorfe model (omdat de menselijke trainer ze niet gemakkelijk allemaal tegelijk kan beschouwen). Om de verwerking te vereenvoudigen, is het raadzaam om het beslissingsproces op te delen in verschillende neurale netwerklagen (zie Fig. 5). De toplaag voert basisevaluaties uit van interne en externe omstandigheden zoals de huidige effectiviteit van de eenheid, het huidige dreigingsniveau, de huidige gevechtsintensiteit en de huidige staat van de missie. Deze netten voeren hun beslissingen over deze voorwaarden in een lager niveau net dat ze samen met de huidige operationele activiteit van de eenheid, eigen intentie en toegewezen taak beschouwt om te komen tot een beslissing over welke operationele activiteit het zal blijven nastreven.
Op bataljonsniveau houdt EAGLE een aantal database-items bij die betrekking hebben op de huidige logistieke toestand van elk bataljon. Het neurale netwerk voor zelfevaluatie groepeert deze items om een evaluatie uit te voeren die de algehele effectiviteit van de eenheid meet en haar huidige vermogen om door te gaan met haar missie.
Het neurale netwerk voor gevechtsevaluatie bepaalt het niveau van het gevecht dat momenteel aan de gang is, indien aanwezig. Het meet het gevechtsniveau als: No Engagement, Light Engagement, Medium Engagement of Heavy Engagement. De netten voor dreigingsevaluatie en missie-evaluatie houden ook rekening met de uitkomst van dit net als onderdeel van hun beslissingsinput.
Het neurale netwerk voor bedreigingsevaluatie beoordeelt de impliciete toestand van de bedreiging. Dit net houdt rekening met informatie zoals de relatieve positie van de vijand en de activiteit van de vijand en komt tot een globale inschatting van de dreiging. Het dreigingsniveau introduceert de waarschijnlijkheid van een gevecht als de eenheid zijn huidige missie voortzet.

Figuur 5. EAGLE evalueert de beslissingsstructuur voor operationele activiteiten
Het neurale net voor missie-evaluatie beoordeelt de huidige staat van de missie van de eenheid, geïmpliceerd door omstandigheden zoals de mate waarin de eenheid momenteel met de vijand bezig is, de staat van de missie ten opzichte van het doel en de huidige activiteit van de eenheid. Dit net bepaalt wat de algehele staat van de missie is. De tweede laag van het netwerk produceert de primaire output van de beslissingsstructuur: de beslissing over wat na te streven als de operationele activiteit. Dit neurale netwerk ontvangt input van de eerstelaags neurale netwerken Gevechtsevaluatie, Dreigingsevaluatie, Missie-evaluatie en Zelfevaluatie en de aanvullende variabelen Operationele Activiteit (feedback van eerdere beslissingen), Bewegingsstatus, Zelfintentie en Taak. Er wordt aangenomen dat Taak de huidige Operatie- of Frag-volgorde van het hogere niveau-commando levert. De output van dit net is een Operationele Activiteit, die bepaalt welke activiteit de eenheid vervolgens zal nastreven.
Een andere functie die door het EAGLE-model wordt vereist, is beslissen wanneer naar een nieuwe doelstelling moet worden overgegaan. Een Evaluate Next Objective neuraal net bepaalt of een eenheid moet overgaan van de toegewezen activiteit naar een andere activiteit (zie Fig. 6). Redenen voor de transitie zijn onder meer de behoefte aan betere zelfverdediging en betere methoden om het doel te bereiken. Inputvoorwaarden omvatten de huidige operationele activiteit, het dreigingsniveau, de effectiviteit van de eenheid, de gevechtsintensiteit en de evaluaties van de missiestatus die zijn gemaakt door de Evaluate Operational Activity Decision Structure. Dit net bepaalt of de eenheid moet overgaan naar een nieuwe doelstelling en retourneert de naam van de functie die de specifieke doelstelling zal bepalen. Mogelijke uitkomsten zijn: doorgaan met huidige doelstelling (dwz geen verandering), volgende geplande doelstelling behalen, uiteindelijke doelstelling behalen, overhaaste gevechtspositie verkrijgen, vijand met de grootste bedreiging aanvallen, breakcontact-doelstelling krijgen en doelstelling dichtstbijzijnde vriendelijke reserve Ground Mobile Unit verkrijgen.

Figuur 6. EAGLE evalueert volgende doelstelling beslissingsstructuur
LINIAC Neural Nets definiëren en trainen
Voordat een neuraal net goed kan functioneren, moet het worden getraind. Training stelt de "neurale" verbindingswaarden (gewichten) vast tussen de invoer- en uitvoervectorelementen van het netwerk. Een LINIAC ANN behoudt zijn opleiding door essentiële informatie op te slaan in een extern tekstbestand. Dit bestand is zowel handig voor het initialiseren van een instantie van een neuraal netwerk in een clienttoepassing als voor het opnieuw invoeren van het trainingsprogramma voor beoordeling of aanvullende training. Clientinitialisatie vindt plaats door de verbindingsmatrixinformatie uit het bestand te laden in een gegevensarchief dat de ANN bijhoudt in de clienttoepassing. Naast de verbindingsmatrix bevat dit bestand informatie om de neurale net-engine in staat te stellen invoer- en uitvoerstatuswaarden toe te wijzen aan de juiste locaties in de invoer- en uitvoervectoren. Het bevat ook de voorbeelden die worden gebruikt voor training, die nuttig kunnen zijn voor latere beoordeling of herscholing.
Pathfinder Systems heeft het programma Course of Action Planner (COAP) ontwikkeld als een op afbeeldingen gebaseerd interactief programma om neurale netwerken eenvoudig te definiëren en te trainen. Eén weergave biedt de mogelijkheid tot netdefinitie, terwijl een tweede weergave de trainingsmogelijkheid biedt. Op elk scherm verschijnen verschillende dialoogvensters met opties voor een compleet trainingsscenario. COAP vervult twee primaire functies; het stelt de gebruiker in staat om de reeks voorwaarden en toestanden te definiëren die het netwerk vormen en het stelt de gebruiker in staat om het neurale netwerk te trainen of te evalueren. Training bestaat uit het geven van een reeks voorbeelden en het bevelen van COAP om het in die voorbeelden gespecificeerde gedrag te leren.
Een neuraal net definiëren
Het venster COAP-definitie biedt twee basisdialoogvensters (zie Fig. 7). Het vak aan de linkerkant stelt de gebruiker in staat om de reeks voorwaarden te definiëren die het neurale netwerk in overweging zal nemen en het meest rechtse vak stelt de gebruiker in staat om de toestanden te specificeren die elke voorwaarde kan aannemen. Voorwaarden en toestanden gebruiken symbolische namen, die consequent worden gebruikt tijdens het definitie- en trainingsproces en voor de daadwerkelijke uitvoering van het neurale net in zijn toepassing.
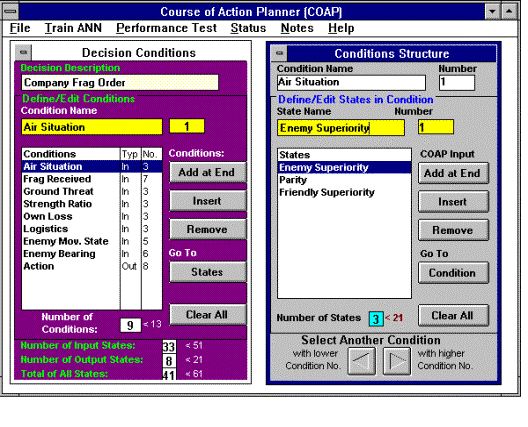
Figuur 7. COAP neurale netdefinitie-interface
Deze symbolische namen definiëren de voorwaarden en hun toestanden met behulp van terminologie die natuurlijk is voor de gebruiker. Het is de taak van de applicatieprogrammeur om de neurale netinterface aan te passen aan de terminologie die de netontwerper heeft aangeleverd; het LINIAC-invoerbestand bevat echter alle symbolische namen die door het neurale netwerk worden gebruikt, wat deze taak aanzienlijk vereenvoudigt. Natuurlijk moet ervoor worden gezorgd dat het neurale net gebruikmaakt van informatie die de toepassing gemakkelijk kan verstrekken en dat de uitkomststaten er ook betekenisvol voor zijn. De gebruiker heeft de vrijheid om voorwaarden en toestanden toe te voegen en te wijzigen totdat de set de vereiste beslissingsvariabelen adequaat vertegenwoordigt. Zodra de training is begonnen, is het mogelijk om de symbolische namen te wijzigen; het toevoegen of verwijderen van voorwaarden of toestanden maakt echter alle eerdere training teniet en vereist dat de training vanaf het begin opnieuw wordt gestart. Eenmaal gedefinieerd, handhaaft COAP de set staat- en conditienamen, trainingsvoorbeelden en verbindingswaarden (de training) in het tekstbestand. Dit bestand moet worden geïmporteerd in de gebruikende applicatie om de verbindingsmatrix te initialiseren.
Neurale Net Training
Het COAP-trainingsvenster biedt de modi Les- en Review-modi (zie Afb. 8). De leermodus biedt online (Direct Drill) en achtergrond (Huiswerk) modi. De training vordert door een reeks invoerwaarden te definiëren en een beslissing van het netwerk te vragen door op de knop "Resultaten weergeven" te klikken. De trainer kan de beslissing accepteren dat het netwerk terugkeert, maar als de beslissing niet wenselijk is, specificeert de trainer de juiste beslissing en instrueert het neurale netwerk om het nieuwe gedrag te "leren". De gebruiker kan aangeven dat het leren online plaatsvindt of dat het als "huiswerk" in de wachtrij wordt geplaatst voor latere batchverwerking. Online training vereist meestal enkele seconden tot enkele minuten per voorbeeld om te verwerken. De tijdsduur hangt voornamelijk af van het aantal voorbeelden dat al in het netwerk is opgenomen en hoe nauw een nieuw voorbeeld een eerder geleerd voorbeeld repliceert. Aangezien dertig tot vijftig voorbeelden voldoende kunnen zijn om aanvaardbare uitvoerbeslissingen te geven over een breed scala aan invoervoorwaarden, kan een gebruiker in staat zijn om een netwerk binnen een periode van enkele uren te trainen. In zeldzame gevallen is het mogelijk dat twee trainingsvoorbeelden patronen vertegenwoordigen die inconsistent zijn, zodat het trainingsalgoritme de verschillen niet kan oplossen (dwz het backpropagation-algoritme kan niet convergeren naar een oplossing). Als dit gebeurt, is het noodzakelijk om de trainingsvoorbeelden te herzien, de anomalieën te elimineren en het netwerk opnieuw te trainen.
In de Review-modus, niet weergegeven in Fig. 8, kan de trainer alle eerdere trainingen bekijken. Aangezien COAP alle trainingsvoorbeelden in zijn externe tekstbestand bewaart, is het mogelijk om de training op te splitsen in meerdere sessies. Zo kan de trainer eerdere training in een latere sessie herzien voor validatie of om overbodige invoer te voorkomen. Dit stelt een gebruiker ook in staat om een neuraal net om te scholen of aanvullende training te geven als de initiële training onjuist of onvoldoende blijkt te zijn voor de beoogde toepassing.
COAP configureert het Trainings- en Evaluatievenster om alle invoervoorwaarden linksboven in het venster weer te geven. Onder elke voorwaardenaam toont COAP alle staten die die voorwaarde definiëren. Tijdens de trainingssessie selecteert de gebruiker een status voor elke voorwaarde voor een specifiek trainingsvoorbeeld en selecteert vervolgens de functie Resultaten weergeven. COAP reageert door de overeenkomstige uitgangsstatus weer te geven die het momenteel "in het geheugen" heeft opgeslagen. De trainer kan op drie manieren reageren: accepteer het resultaat als het overeenkomt met de gewenste resultaten, verwerp het resultaat of negeer het. Als de trainer de uitkomst afwijst, biedt COAP de mogelijkheid om het juiste antwoord te specificeren en vraagt de trainer vervolgens om te beginnen met leren. Leren vindt plaats door de verbindingsmatrixwaarden aan te passen, zodat het net het gewenste resultaat voor de gegeven stimulus zal produceren zonder eerder geleerd gedrag te schenden. Omdat neurale netwerken eerder geleerde patronen kunnen extrapoleren om overeen te komen met vergelijkbare invoerpatronen, is het voor de trainer niet nodig om veel vergelijkbare patronen te presenteren om het netwerk effectief te trainen. Dit vermogen om te extrapoleren vermindert de trainingstijd aanzienlijk en maakt het neurale net tot een zeer kosteneffectief hulpmiddel.

Figuur 8. COAP neurale net-trainingsinterface
Een andere COAP-functie die beschikbaar is in de beoordelingsmodus is de optie Prestatietest. Deze optie voert een aantal opeenvolgende uitvoeringen van het neurale net uit en geeft de gemiddelde uitvoeringstijd aan de gebruiker weer. De gemiddelde tijd varieert van enkele milliseconden tot enkele tientallen milliseconden op een 33 MHz 80486 pc, afhankelijk van de complexiteit van het neurale netwerk. Dit contrasteert gunstig met veel andere huidige neurale net-implementaties, die aanzienlijke rekentijden vereisen. De snelheid van de berekeningscyclus van LINIAC maakt het behoorlijk aantrekkelijk voor veel toepassingen, omdat het doorgaans een tot meerdere ordes van grootte sneller kan uitvoeren dan vergelijkbare op regels gebaseerde of algoritmische implementaties.
Conclusie
Dit artikel heeft een praktische benadering gepresenteerd voor het gebruik van kunstmatige neurale netwerken om geautomatiseerde besluitvorming uit te voeren in de context van gevechtssimulaties. Neurale netten kunnen veel gemakkelijker te ontwerpen en te implementeren zijn dan vergelijkbare algoritmen of regelbases. Een enkele neurale net-engine kan fungeren als een server voor een willekeurig aantal neurale netwerken. De "code" die nodig is om een neuraal net uit te voeren, kan worden ingekapseld in een extern gegevensbestand, inclusief zowel de verbindingsmatrix als de conditie-/statusdefinities voor de invoer- en uitvoervectoren. Door deze externe codering kan het gedrag van een client eenvoudig worden gewijzigd door een anders getrainde ANN te vervangen zonder de broncode te wijzigen. Dit vermindert de hoeveelheid tijd en de kosten die nodig zijn voor het ontwerpen, implementeren en onderhouden van beslissingslogica/code voor geautomatiseerde krachten aanzienlijk. In simulaties biedt dit essentiële flexibiliteit omdat het gedrag van geautomatiseerde krachten mogelijk moet veranderen om verschillende scenario's weer te geven. Dit maakt het ook mogelijk om neurale netten te vervangen waarvan de initiële training tekortkomingen kan bevatten.
Omdat het mogelijk is om neurale netwerken te trainen met behulp van een relatief eenvoudige grafische interface, is het mogelijk om "experts" ze snel en direct te laten trainen zonder tussenliggend technisch personeel dat onbedoeld persoonlijke vooroordelen in de beslissingsbasis kan introduceren. Deze gebruikersinterface biedt ook de mogelijkheid om de training en het gedrag van een neuraal net te beoordelen en biedt dus een eerste validatie van het gedrag van het net. Neurale netwerken weerspiegelen hun trainingsvoorbeelden zeer getrouw en vermijden onnodige fouten veroorzaakt door coderingsafwijkingen. Ze zijn ook erg goed in het weergeven van het gedrag door geleerde voorbeelden te extrapoleren naar omstandigheden waarvoor ze geen afzonderlijke training hebben gehad, wat de tijd die experts moeten besteden aan het trainen van hen aanzienlijk verkort. De neurale netimplementatie van LINIAC heeft een zeer hoge uitvoeringssnelheid, en zelfs een structuur van meerdere neurale netwerken die opeenvolgend werken om een enkele beslissing te produceren, kan gemakkelijk een vergelijkbare algoritmische of op regels gebaseerde implementatie overtreffen. Ten slotte heeft PSI hun prestaties, betrouwbaarheid en nauwkeurigheid geverifieerd in verschillende demonstratieprojecten.